By Kousik Nath
Problem Statement:
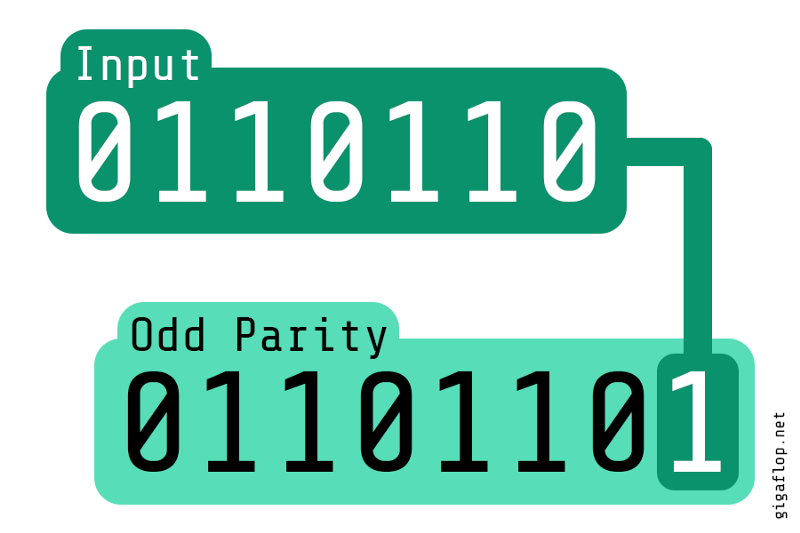
You are getting a stream of numbers (say long type numbers), compute the parity of the numbers. Hypothetically you have to serve a huge scale like 1 million numbers per minute. Design an algorithm considering such scale. Parity of a number is 1 if the total number of set bits in the binary representation of the number is odd else parity is 0.
Solution:
Approach 1 - Brute Force:
The problem statement clearly states what parity is. We can calculate the total number of set bits in the binary representation of the given number. If the total number of set bits is odd, parity is 1 else 0. So the naive way is to keep doing a bit-wise right shift on the given number & check the current least significant bit (LSB) to keep track of the result.

In the above code snippet, we are going through all the bits in the while loop one by one. With the condition ((no & 1) == 1) , we check if the current LSB is 1 or 0 , if 1 , we do result ^= 1 . The variable result is initialized to 0 . So when we do xor (^) operation between the current value of result & 1 , the result will be set to 1 if the result is currently 0 , otherwise 1 .
If there are an even number of set bits, eventually the result will become 0 because xor between all 1’s will cancel out each other. If there are an odd number of 1’s, the final value of result will be 1. no >>> 1 right shifts the bits by 1.
>;>> is logical right shift operator in java which shifts the sign bit (the most significant bit in a signed number) as well. There is another right shift operator — >> which is called arithmetic right s_hift operator [see reference 1 at the l_ast of the page]. It does not shift the sign bit in the binary representation — the sign bit remains intact at its position. Finally result & 0x1 returns 1 if there is parity or 0 otherwise.
Advantages:
- The solution is very easy to understand & implement.
Disadvantages:
- We are processing all the bits manually, so this approach is hardly efficient at scale.
Time Complexity: O(n) where n is the total number of bits in the binary representation of the given number.
Approach 2 - Clear all the set bits one by one:
There is a bottleneck in the above solution: the while loop itself. It just goes through all bits one by one, do we really need to do that? Our concern is about set bits, so we are not getting any benefits by going over unset bits or 0 bits. If we can just go over only set bits, our solution becomes little more optimized. In bitwise computation, if we are given a number n, we can clear the rightmost set bit with the following operation:
n = n & (n-1)
Take an example: say n = 40, the binary representation in 8-bit format is: 00101000.
n = 0010 1000
n - 1 = 0010 0111
n & (n - 1) = 0010 0000
We have successfully cleared the lowest set bit (4th bit from the right side). If we keep doing this, the number n will become 0 at a certain point in time. Based on this logic, if we compute parity, we don’t need to scan all bits. Rather we scan only k bits where k is the total number of set bits in the number & k <= length of the binary representation. Following is the code:
Advantages:
- Simple to implement.
- More efficient than brute force solution.
Disadvantages:
- It’s not the most efficient solution.
Time Complexity:
O(k) where k is the total number of set bits in the number.
Approach 3 - Caching:
Look at the problem statement once more, there’s definitely a concern about scale. Can our earlier solutions scale to serve millions of requests or still is there any scope to do better?
We can probably make the solution faster if we can store the result in memory — caching. In this way we can save some CPU cycles to compute the same result. So if the total number of bits is 64 , how much memory do we need to save all possible numbers? 64 bits will lead us to have Math.pow(2, 64) possible signed numbers (the most significant bit is used to store only sign). The size of a long type number is 64 bits or 8 bytes, so total memory size required is: 64 * Math.pow(2, 64) bits or 134217728 TeraBytes. This is too much & is not worth it to store such a humongous amount of data. Can we do better?
We can break the 64 bits number into a group of 16 bits, fetch the parity of those individual group of bits from cache & combine them. This solution works because 16 divides 64 into 4 equal parts & we are concerned just about the total number of set bits. So as far as we are getting parity of those individual group of bits, we can xor their results with each other, since xor is associative & commutative. The order in which we fetch those group of bits & operate on them does not even matter.
If we store those 16 bit numbers as an integer, total memory required is: Math.pow(2, 16) * 32 bits = 256 Kilo Bytes.

In the above snippet, we shift a group of 16 bits by i * WORD_SIZE where0 ≤ i ≤ 3 and do bitwise AND operation (&) with a mask = 0xFFFF (0xFFFF = 1111111111111111 ) so that we can just extract the rightmost 16 bits as integer variables like masked1, masked2 etc, we pass these variables to a method checkAndSetInCache which computes the parity of this number in case it’s not available in the cache. In the end, we just do xor operation on the result of these group of numbers which determines the final parity of the given number.
Advantages:
- At the cost of relatively small memory for the cache, we get better efficiency since we are reusing a group of 16-bit numbers across inputs.
- This solution can scale well as we are serving millions of numbers.
Disadvantages:
- If this algorithm needs to be implemented in an ultra-low memory device, the space complexity has to be well thought of in advance in order to decide whether it’s worth it to accommodate such amount of space.
Time Complexity:
O(n / WORD_SIZE) where n is the total number of bits in the binary representation. All right / left shift & bitwise &, |, ~ etc operations are word level operations which are done extremely efficiently by CPU. Hence their time complexity is supposed to be O(1).
Approach 4 - Using XOR & Shifting operations:
Let’s consider this 8-bit binary representation: 1010 0100. The parity of this number is 1. What happens when we do a right shift on this number by 4 & xor that with the number itself?
n = 1010 0100
n >>> 4 = 0000 1010
n ^ (n >> 4) = 1010 1110
n = n ^ (n >>> 4) = 1010 1110 (n is just assigned to the result)
In rightmost 4 bits, all the bits are set which are different in n & n >>> 4 . Now let’s concentrate on this right most 4 bits only: 1110 , let’s forget about other bits. Now n is 1010 1110 & we are just concentrated on the lowest 4 bits i.e; 1110. Let’s do a bitwise right shift on n by 2.
n = 1010 1110
n >>> 2 = 0010 1011
n ^ (n >>> 2) = 1000 0101
n = n ^ (n >>> 2) = 1000 0101 (n is just assigned to the result)
Just concentrate on the rightmost 2 bits now & forget about leftmost 6 bits. Let’s right shift the number by 1:
n = 1000 0101
n >>> 1 = 0100 0010
n ^ (n >>> 1) = 1100 0111
n = n ^ (n >>> 1) = 1100 0111 (n is just assigned to the result)
We don’t need to right shift anymore, we just now extract the LSB bit which is 1 in the above case & return the result: result = (short) n & 1 .
At a glance, the solution might look a little confusing, but it works. How? We know that 0 xor 1 or 1 xor 0 is 1, otherwise 0. So when we divide the binary representation of a number into two equal halves by length & we do xor between them, all different pair of bits result into set bits in the xor-ed number.
Since parity occurs when an odd number of set bits are there in the binary representation, we can use xor operation to check if an odd number of 1 exists there. Hence we right shift the number by half of the total number of digits, we xor that shifted number with the original number, we assign the xor-ed result to the original number & we concentrate only on the rightmost half of the number now. So we are just xoring half of the numbers at a time & reduce our scope of xor. For 64 bit numbers, we start xoring with 32 bit halves, then 16 bit halves, then 8, 4, 2, 1 respectively.
Essentially, parity of a number means parity of xor of equal halves of the binary representation of that number. The crux of the algorithm is to concentrate on rightmost 32 bits first, then 16, 8, 4 , 2 , 1 bits & ignore other left side bits. Following is the code:

Advantages:
- No extra space uses word-level operations to compute the result.
Disadvantages:
- Might be little difficult to understand for developers.
Time Complexity:
O(log n) where n is the total number of bits in the binary representation.
Following is the full working code:
import java.util.Arrays;
public class ParityOfNumber {
private static short computeParityBruteForce(long no) {
int result = 0;
while(no != 0) {
if((no & 1) == 1) {
result ^= 1;
}
no >>>= 1;
}
return (short) (result & 0x1);
}
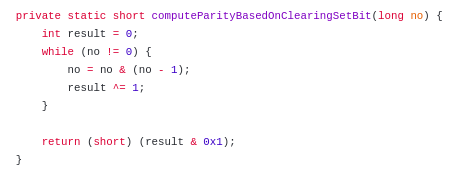
private static short computeParityBasedOnClearingSetBit(long no) {
int result = 0;
while (no != 0) {
no = no & (no - 1);
result ^= 1;
}
return (short) (result & 0x1);
}
private static short computeParityWithCaching(long no) {
int[] cache = new int[(int) Math.pow(2, 16)];
Arrays.fill(cache, -1);
int WORD_SIZE = 16;
int mask = 0xFFFF;
int masked1 = (int) ((no >>> (3 * WORD_SIZE)) & mask);
checkAndSetInCache(masked1, cache);
int masked2 = (int) ((no >>> (2 * WORD_SIZE)) & mask);
checkAndSetInCache(masked2, cache);
int masked3 = (int) ((no >>> WORD_SIZE) & mask);
checkAndSetInCache(masked3, cache);
int masked4 = (int) (no & mask);
checkAndSetInCache(masked4, cache);
int result = (cache[masked1] ^ cache[masked2] ^ cache[masked3] ^ cache[masked4]);
return (short) (result & 0x1);
}
private static void checkAndSetInCache(int val, int[] cache) {
if(cache[val] < 0) {
cache[val] = computeParityBasedOnClearingSetBit(val);
}
}
private static short computeParityMostEfficient(long no) {
no ^= (no >>> 32);
no ^= (no >>> 16);
no ^= (no >>> 8);
no ^= (no >>> 4);
no ^= (no >>> 2);
no ^= (no >>> 1);
return (short) (no & 1);
}
public static void main(String[] args) {
long no = 1274849;
System.out.println("Binary representation of the number: " + Long.toBinaryString(no));
System.out.println("Is Parity [computeParityBruteForce]: " + computeParityBruteForce(no));
System.out.println("Is Parity [computeParityBasedOnClearingSetBit]: " + computeParityBasedOnClearingSetBit(no));
System.out.println("Is Parity [computeParityMostEfficient]: " + computeParityMostEfficient(no));
System.out.println("Is Parity [computeParityWithCaching]: " + computeParityWithCaching(no));
}
}
Learning from this exercise:
- Although it’s basic knowledge, I want to mention that word level bitwise operations is constant in time.
- At a scale, we can apply caching by breaking down the binary representation into equal halves of suitable word size like
16in our case so that we can accommodate all possible numbers in memory. Since we are supposed to handle millions of numbers, we will end up reusing16bit groups from cache across numbers. The word size does not necessarily need to be16, it depends on your requirement & experiments. - You don’t need to store the binary representation of a number in the separate array to operate on it, rather clever use of bitwise operations can help you achieve your target.
References:
[1]. https://stackoverflow.com/questions/2811319/difference-between-and
[2]. https://gist.github.com/kousiknath/b0f5cd204369c5cd1669535cc9a58a53