

Hi everyone! In this article we're going to take a look at a key topic when it comes to programming: managing asynchronism.
We'll start by giving a theoretical foundation about what asynchronism is, and how it relates to key components of JavaScript: The execution thread, the call stack and the event loop.
And then I'm going to present the three ways in which we can handle asynchronous tasks in JavaScript: Callbacks, promises and async/await.
Sounds fun, right? Let's go!
Table of Contents
What is Asynchronism?
Any computer program is nothing but a series of tasks we require the computer to execute. In JavaScript, tasks can be classified into synchronous and asynchronous types.
Synchronous tasks are the ones that execute sequentially, one after the other, and while they're being executed nothing else is being done. At each line of the program, the browser waits for the task to finish before jumping to the next one.
We say this kind of tasks are "blocking", because while they execute they block the execution thread (I'm going to explain what this is in a sec), preventing it from doing anything else.
Asynchronous tasks, on the other hand, are the ones that, while they execute, they don't block the execution thread. So the program can still perform other tasks while the asynchronous task is being executed.
This is why we say this kind of tasks are "non blocking". This technique comes in handy specially for tasks that take long time to execute, as by not blocking the execution thread the program is able to execute more efficiently.
According to Mozilla docs:
Asynchronous programming is a technique that enables your program to start a potentially long-running task and still be able to be responsive to other events while that task runs, rather than having to wait until that task has finished. Once that task has finished, your program is presented with the result.
Asynchronism in JavaScript
Now that we have a more or less clear idea of what asynchronism is, let's get into the complicated interesting stuff – how JavaScript makes this possible.
One of the first apparent paradoxes of JavaScript – and there are a few – that you'll encounter when learning about the language is that JavaScript is a single threaded language.
"Single threaded" means it has a single thread of execution. This means that JavaScript programs can only execute a single task at a time.
This isn't the case, for example, for languages like Java or Ruby, which can create various execution threads and in that way execute many tasks simultaneously.
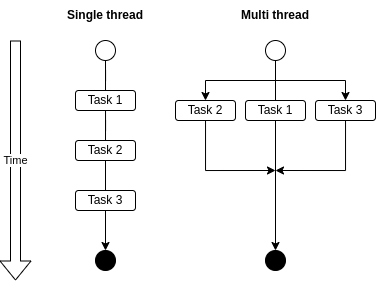
Visualizing single thread vs multi thread execution
And here the paradox is: if JavaScript can only execute only one task at a time, how come synchronous tasks can execute while asynchronous tasks complete "in the background"? How come asynchronous tasks don't block the execution thread? How are they executed then?
To explain this, we need to briefly describe how web browsers execute JavaScript code and some of its core components: The call stack, web APIs, the callback queue, and the event loop.
What is the Call Stack?
As you may now, a stack is a type of data structure where elements are added and removed following a LIFO (last in, first out) pattern. Browsers use something called the call stack to read and execute each task contained in a Javascript program.
Side comment: If you're not familiar with data structures, you can take a look at this article I wrote a while ago.
The way it works is quite simple. When a task is to be executed, it's added to the call stack. When it's finished, it's removed from the call stack. This same action is repeated for each and every task until the program is fully executed.
Let's see this with an easy example. If we had these three lines of code:
console.log('task 1')
console.log('task 2')
console.log('task 3')
Our call stack would look like this:

Illustration of an example call stack
Call stack starts off empty at the start of the program.
The first task is added to the call stack and executed.
The first task is removed from the call stack once finished.
The second task is added to the call stack and executed.
The second tasks is removed from the call stack once finished.
The third task is added to the call stack and executed.
The third task is removed from the call stack once finished. End of the program.
Easy right? Now let's see a slightly more complicated example with these lines of code:
const multiply = (a, b) => a*b
const square = n => multiply(n, n)
const printSquare = n => console.log(square(n))
printSquare(4)
Here we're calling printSquare(), which itself calls square(), which itself calls multiply(). With this program, our call stack might look like this:
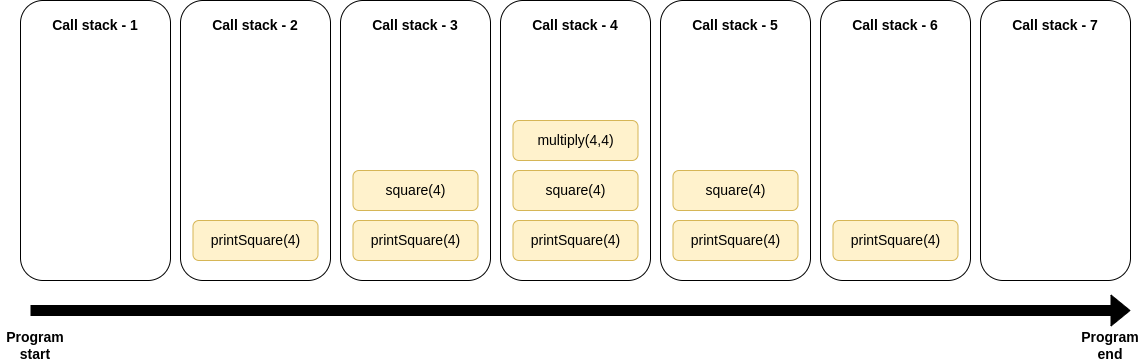
Another more complex example of a call stack
Call stack starts off empty at the start of the program.
printSquare(4)is added to the call stack and executed.As
printSquare(4)calls the functionsquare(4),square(4)is added to the call stack and executed as well. Note that as the execution ofprintSquare(4)isn't finished yet, it's kept on the stack.As
square(4)callsmultiply(4,4),multiply(4,4)is added to the call stack and executed as well.multiply(4,4)is removed from the call stack once finished.square(4)is removed from the call stack once finished.printSquare(4)is removed from the call stack once finished. End of the program.
In this example we can clearly see the LIFO pattern the call stack uses to add and remove tasks to it.
The important thing to notice here is that tasks are not removed from the stack until they're finished. This is how synchronous callbacks work.
When a function calls another function, the callback is added to the stack and executed. Once the execution of the callback is completed, it's removed from the stack and the execution of the main function is completed.
Web APIs, the Callback Queue, and the Event Loop
So far so good, right? Using the call stack, JavaScript takes account of each task, executes it, and then moves on to the next. Fairly simple.
Now let's check the following example:
console.log('task1')
setTimeout(() => console.log('task2'), 0)
console.log('task3')
Here, we're logging three separate strings, and on the second one we're using setTimeout to log it after 0 milliseconds. Which should be, according to common logic, instantly. So one should expect the console to log: "task1", then "task2", and then "task3".
But that's not what happens:

And if we had a look at our call stack during the program, It would look like this:
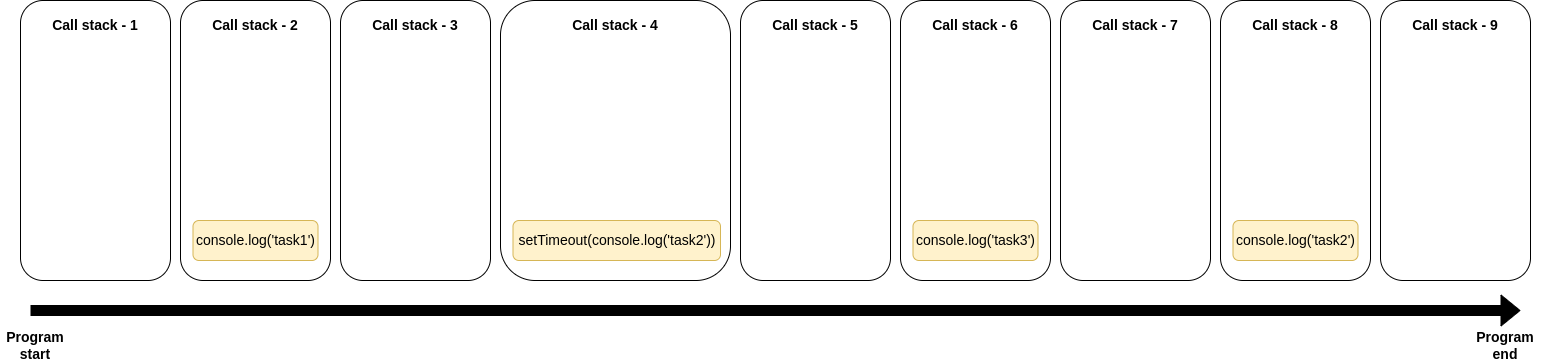
Call stack starts off empty at the start of the program.
console.log('task1')is added to the call stack and executed.console.log('task1')is removed from the call stack once finished.setTimeout(console.log('task2'))is added to the call stack, but it's not executed.setTimeout(console.log('task2'))"mysteriously" disappears from the call stack.console.log('task3')is added to the call stack and executed.console.log('task4')is removed from the call stack once finished.console.log('task2')"mysteriously" hops into the call stack and is executed.console.log('task2')is removed from the call stack once finished.
To explain this "mysterious" disappearance and reappearance of the setTimeout task, we need to introduce three more components that are part of the browser runtime: Web APIs, the callback queue, and the event loop.
What are Web APIs?
Web APIs are a set of features and functionalities that the browser uses to enable JavaScript to execute. These features include DOM manipulation, AJAX calls, and setTimeout among other things.
To simplify the understanding of this, think about it like a different "execution place" rather than the call stack. When the call stack detects that the task it's processing is web API-related, it asks the web API "Hey API, I need to get this done", and the web API takes care of it, allowing the call stack to continue with the next task in the stack.
What are the callback queue and the event loop?
In the code example we saw before, we saw that setTimeout(console.log('task2')) "mysteriously" disappeared from the call stack. We now know that, it didn't actually disappear – it was sent to the web API.
But then it "mysteriously" reappeared again, so how does that work? Well, that's the job of the callback queue and the event loop.
The callback queue is a queue that stores the tasks that the web APIs return. Once the web API finishes executing the given task (which in this case was processing the setTimeout) it sends the callback to the callback queue.
Queues are a type of data structure where elements are added and removed following a FIFO pattern (first in, first out). Again, if you're not familiar with data structures, you can take a look at this article.
The event loop is a loop (woah... really?) that constantly checks two things:
If the call stack is empty
If there's any task present in the callback queue
If both of these conditions are met, then the task present in the callback queue is sent to the call stack to complete its execution.
Now that we know about web APIs, the callback queue, and the event loop, we can know what actually happened in our previous example:

Following the red lines, we can see that when the call stack identified that the task involved setTimeout, it sent it to the web APIs to process it.
Once the web APIs processed the task, it inserted the callback into the callback queue.
And once the event loop detected that the call stack was empty and that there was a callback present in the callback queue, it inserted the callback in the call stack to complete its execution.
This is how JavaScript makes asynchronism possible. Asynchronous tasks are processed by web APIs instead of the call stack, which handles only synchronous tasks.
In this way, the call stack can just derive asynchronous tasks to web APIs and carry on executing whatever else is present on the stack. And thanks to the callback queue and the event loop, once the asynchronous task was handled by the web APIs, the callback is reinserted into the call stack.
It's important to remember that JavaScript always runs only one task at a time. The "magic" of asynchronism is made possible by the existence of the web APIs, the callback queue, and the event loop, which are responsible for managing asynchronous tasks.
Side comment: If you wonder how all this works on Node instead of a browser, it's fairly similar. Instead of web APIs you have C++ APIs. The call stack, the callback queue, and the event loop work exactly the same.
If you want a more detailed explanation of all these topics, I recommend that you take a look at this very well known talk by Philip Roberts.
So How Do We Code This Stuff... ?
Now that we have the theoretical foundation of how JavaScript makes asynchronism possible, let's see how all this implements in code.
There are mainly three ways in which we can code asynchronism in JavaScript: callback functions, promises, and async-await.
I'll present them in the chronological order JavaScript has provided these features (first there were only callback functions, then came promises, and lastly async-await). But keep in mind that the most common and recommended practice nowadays is to use async-await. ;)
How Callback Functions Work
Callbacks are functions that are passed as arguments to other functions. The function that takes the argument is called a "Higher order function", and the function that is passed as an argument is called a "Callback".
We can see this in practice in the following example:
const callbackFunc = () => console.log('Im the callback')
const higherOrderFunction = callback => callback()
higherOrderFunction(callbackFunc)
Side comment: the possibility of passing functions as parameters to other functions is one of the features that make functions first class citizens in JavaScript.
The difference between synchronous and asynchronous callbacks relies on the type of task that function executes. There's no syntactic difference between each kind. Let's see this in code.
const arr = [1,2,3]
console.log('logging...')
arr.map(e => console.log('sync item', e)) // This is a synchronous callback
arr.map(e => setTimeout(() => console.log('async item', e), 0)) // This is an asynchronous callback
console.log('the stuff')
Here we have an array of three elements, a couple of console.logs, and two map functions. What map does is iterate over each element of the array and perform a function for each element in the array. That function is defined as a callback.
In the first map, we are logging the item with console.log. In the second one, we're doing the same but using setTimeout (which as we saw before is an asynchronous task performed by web APIs).
As a result, our console will look like this:

First, all the synchronous callbacks are executed, and then the asynchronous callbacks kick in.
As we can see, the fact that the functions execute asynchronously isn't related to the fact that they're callbacks or not, but rather to the kind of task that function executes. As setTimeout is an async task, those callbacks are executed asynchronously.
How Promises Work
A more modern approach for dealing with asynchronism is by using promises. A promise is a special kind of object in JavaScript that has 3 possible states:
Pending: It's the initial state, and it signifies that the corresponding task is yet to be resolved.
Fulfilled: Means the task has been completed successfully.
Rejected: Means the task has produced some kind of error.
To see this in practice, we'll use a realistic case in which we fetch some data from an API endpoint and log that data in our console. We'll use the fetch API provided by browsers and a public API that returns Chuck Norris jokes.
Here our function executes a GET HTTP request to the endpoint, and we use the then and catch methods that the promise object has to process the promise response.
const fetchJokeWithPromises = () => {
console.log('fetching with promises...')
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(res => console.log('res', res))
.catch(error => console.error('There was an error!', error))
}
fetchJokeWithPromises()
But let's take a closer look at this step by step.
- If we log just the fetch line, like this:
console.log('fetch', fetch('https://api.chucknorris.io/jokes/random'))
We see we get a promise with a pending state:

- Then if we execute the first
thenmethod and log its result, we get the following:
fetch('https://api.chucknorris.io/jokes/random')
.then(res => console.log('res', res))
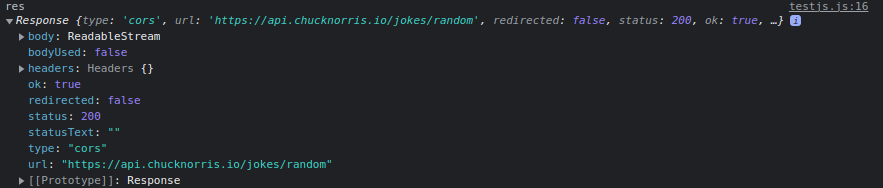
We see here we no longer have a promise, but the actual response from the endpoint. The then method waits for the promise to complete, and then provides us with the result, which is present as a parameter for the method.
- But to read the actual response body (which in our console we can see its a
ReadableStream), we have to call the.json()method on it. This itself returns another promise. That's why we need another.then().
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(responseBody => console.log('responseBody', responseBody))

And here, finally we can see the full response and our joke in the value property. ;)
- What the
catchmethod does is execute whenever a promise is rejected. Normallycatchis used to handle an error, like showing a certain message to the user when an API fails to respond.
To see it in action, let's use a random endpoint like this one:
fetch('https://asdadsasdasd/')
.then(res => res.json())
.then(resp => console.log('resp', resp))
.catch(error => console.error('There was an error!', error))
And in our console we can see the catch method executed:

An important thing to notice is in situations like this one, where we have various .then methods chained, we only need to use one .catch method. This is because that one .catch will process the errors in all of the promises chained.
Again, to see this in action now, let's go back to our previous endpoint and mess with the .json() call, misspelling it now.
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.jon())
.then(resp => console.log('resp', resp))
.catch(error => console.error('There was an error!', error))

To round up promises, there's an additional method provided by promises which is .finally. This will execute always once the promise has been resolved, either successfully or not.
fetch('https://api.chucknorris.io/jokes/random')
.then(res => res.json())
.then(resp => console.log('resp', resp))
.catch(error => console.error('There was an error!', error))
.finally(() => console.log('Promised resolved!'))
How Async-Await Works
Async-await is the latest way of dealing with asynchronism provided by JavaScript. Basically, it's just syntactic sugar that allow us to deal with promises in a more concise way than using .then methods.
Let's see this in action following the same previous example.
const fetchJokeWithAsyncAwait = async () => {
try {
const res = await fetch('https://api.chucknorris.io/jokes/random')
const data = await res.json()
console.log('async-await data', data)
} catch (error) {
console.error('There was an error!', error)
}
}
fetchJokeWithAsyncAwait()
Here we have a function that executes the fetch and logs the response. See that we start by using the async keyword when we declare the function. This is a requirement for all functions that use async-await.
Then we enclose our fetch call in a try-catch statement. This is required because with async-await we won't use the .catch method. But we still need to process possible errors.
We achieve this with the use of try-catch. If anything contained in the try statement returns an error, then the catch statement executes, obtaining the error as a parameter.
As you can see, we are assigning the result of the fetch call to a variable called res. And before the fetch we're using the await keyword.
const res = await fetch('https://api.chucknorris.io/jokes/random')
This means that Javascript will wait for the promise to resolve before assigning its value to the variable. And any operations done on that variable, will only execute once its value has been assigned.
In the next line we're calling the .json() method on the res variable, and again using the await keyword before it so the promise result is then assigned to the data variable.
And lastly, we log our data.

As mentioned, async-await is just syntactic sugar. It doesn't do anything differently than .then and .catch methods. It's just easier to write and read.
Wrap-up
Well everyone, as always, I hope you enjoyed the article and learned something new.
If you want, you can also follow me on LinkedIn or Twitter. See you in the next one!
