By Tim Grossmann
What I learned building the StateOfVeganism ?
By now, we all know that news and media shape our views on the topics we discuss. Of course, this is different from person to person. Some might be influenced a little more than others, but there always is some opinion communicated.
Considering this, I thought it would be really interesting to see the continuous development of mood directed towards a specific topic or person in the media.
For me, Veganism is an interesting topic, especially since it is frequently mentioned in the media. Since the media’s opinion changes the opinion of people, it would be interesting to see what “sentiment” they communicate.

This is what this whole project is about. It collects news that talks about or mentions Veganism, finds out the context in which it was mentioned, and analyses whether it propagates negativity or positivity.
Of course, a huge percentage of the analysed articles should be classified as “Neutral” if the writers do a good job in only communicating information, so we should keep that in mind, too.
I realized that this was an incredible opportunity to pick up new toolset, especially when I thought about the sheer number of articles published daily.
So, I thought about building a scalable architecture — one that is cheap/free in the beginning when there is no traffic and only a few articles, but scales easily and infinitely once the amount of mentions or traffic increases. I heard the cloud calling.
Designing the Architecture
Planning is everything, especially when we want to make sure that the architecture scales right from the beginning.
Starting on paper is a good thing, because it enables you to be extremely rough and quick in iterating.
Your first draft will never be your final one, and if it is, you’ve probably forgotten to question your decisions.
For me, the process of coming up with a suitable and, even more important, reasonable architecture was the key thing I wanted to improve with this project. The different components seemed pretty “easy” to implement and build, but coming up with the right system, the right communication, and a nice, clean data pipeline was the really interesting part.
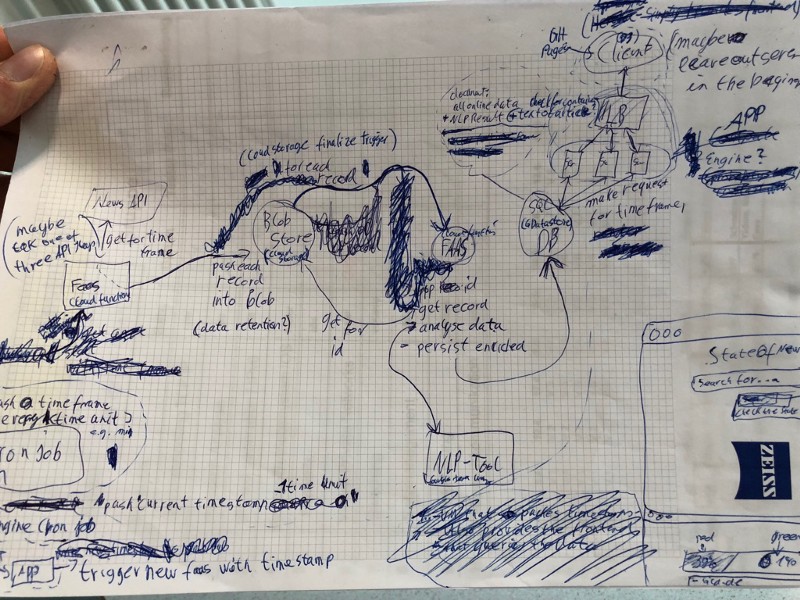 First Concept with removed components
First Concept with removed components
In the beginning, I had some bottlenecks in my design which, at one point, would’ve brought my whole system to its knees. In that situation, I thought about just adding more “scalable” services like queues to queue the load and take care of it.
When I finally had a design which, I guessed, could handle a ton of load and was dynamically scalable, it was a mess: too many services, a lot of overhead, and an overall “dirty” structure.
When I looked at the architecture a few days later, I realised that there was so much I could optimise with a few changes. I started to remove all the queues and thought about replacing actual virtual machines with FAAS components.
After that session, I had a much cleaner and still scalable design.
Think of the structure and technologies, not implementations
That was one of the mistakes I made quite early in the project. I started out by looking at what services IBM’s BlueMix could offer and went on from there. Which ones could I mix together and use in my design that seemed to work together with triggers and queues and whatever?
In the end, I could remove a lot of the overhead in terms of services by simply stepping away from it and thinking of the overall structure and technologies I needed, rather than the different implementations.
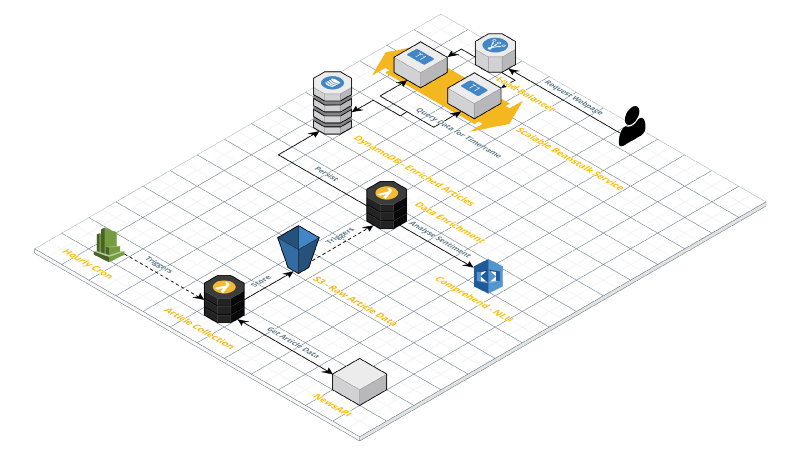
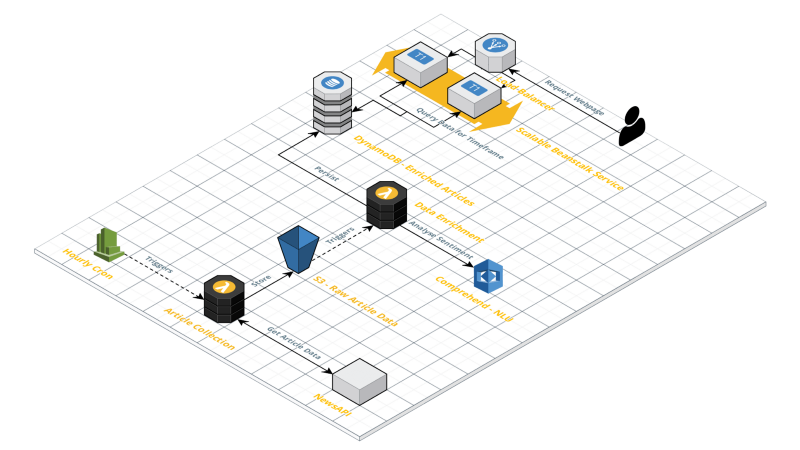 Final Architecture
Final Architecture
Broken down into a few distinct steps, the project should:
- Every hour (in the beginning, since there would only be a few articles at the moment -> could be made every minute or even every second) get the news from some NewsAPI and store it.
- Process each article, analyse the sentiment of it, and store it in a database to query.
- Upon visiting the website, get the selected range data and display bars/articles.
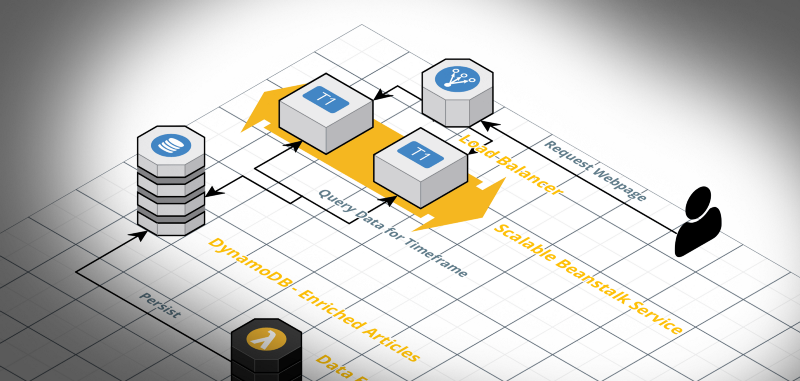
So, what I finally ended up with was a CloudWatch Trigger which triggers a Lambda Function every hour. This Function gets the news data for the last hour from the NewsAPI. It then saves each article as a separate JSON file into an S3 bucket.
This bucket, upon ObjectPut, triggers another Lambda Function. This loads the JSON from S3, creates a “context” for the appearance of the part-word “vegan,” and sends the created context to the AWS Comprehend sentiment analysis. Once the function gets the sentiment information for the current article, it writes it to a DynamoDB table.
This Table is the root for the data displayed in the frontend. It gives the user a few filters with which they can explore the data a little bit more.
If you’re interested in a deeper explanation, jump down to the description of the separate components.
Who’s “The One” Cloud Provider?
Before I knew that I was going with AWS, I tried out two other cloud providers. It’s a very basic and extremely subjective view on which provider to choose, but maybe this will help some other “Cloud-Beginners” choose.
I started out with IBMs Bluemix Cloud, moved to Google Cloud, and finally ended up using AWS. Here are some of the “reasons” for my choice.
A lot of the points listed here really only tell how good the overall documentation and community is, how many of the issues I encountered that already existed, and which ones had answers on StackOverflow.
Documentation and Communities are Key
Especially for beginners and people who’ve never worked with cloud technologies, this is definitely the case. The documentation and, even more importantly, the documented and explained examples were simply the best for AWS.
Of course, you don’t have to settle for a single provider. In my case, I could’ve easily used Google’s NLU tools because, in my opinion, they brought the better results. I just wanted to keep my whole system on one platform, and I can still change this later on if I want to.
The starter packs of all providers are actually really nice. You’ll get $300 on Google Cloud which will enable you to do a lot of stuff. However, it’s also kind of dangerous, since you’ll be charged if you should use up the amount and forget to turn off and destroy all the services building up the costs.
BlueMix only has very limited access to services on their free tier, which is a little bit unfortunate if you want to test out the full suite.
Amazon, for me, was the nicest one, since they also have a free tier which will allow you to use nearly every feature (some only with the smallest instance like EC2.micro).
Like I already mentioned, this is a very flat and subjective opinion on which one to go for… For me AWS was the easiest and fastest to pick up without investing too much time upfront.
The Components
The whole project can basically be split into three main components that need work.
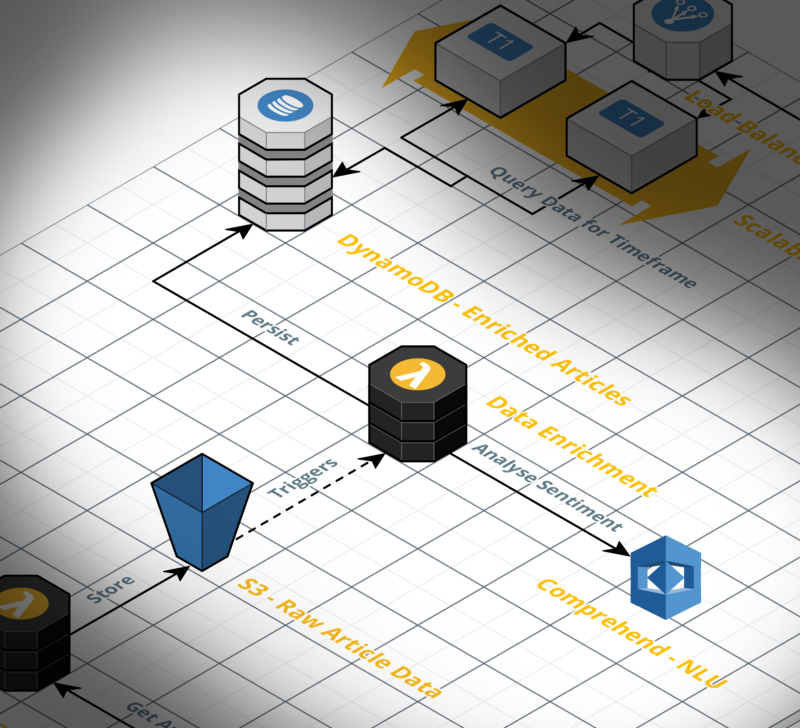
The Article Collection, which consists of the hourly cron job, the lambda function which calls the NewsAPI, and the S3 bucket that stores all the articles.
The Data Enrichment part which loads the article from S3, creates the context and analyses it using Comprehend, and the DynamoDB that stores the enriched data for later use in the frontend.
And the Frontend which gets displayed when the users request the webpage. This component consists of a graphical user interface, a scalable server service which serves the webpage, and, again, the DynamoDB.
![]()
Article Collection
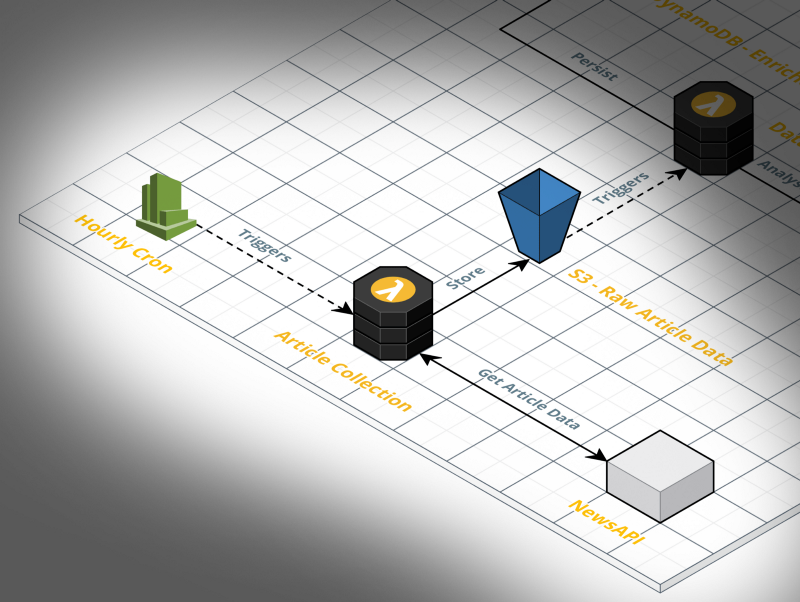 Article Collection Part
Article Collection Part
The first and probably easiest part of the whole project was collecting all the articles and news that contain the keyword “vegan”. Luckily, there are a ton of APIs that provide such a service.
One of them is NewsAPI.org.
With their API, it’s extremely easy and understandable. They have different endpoints. One of them is called “everything” which, as the name suggests, just returns all the articles that contain a given keyword.
Using Node.js here, it looks something like this:
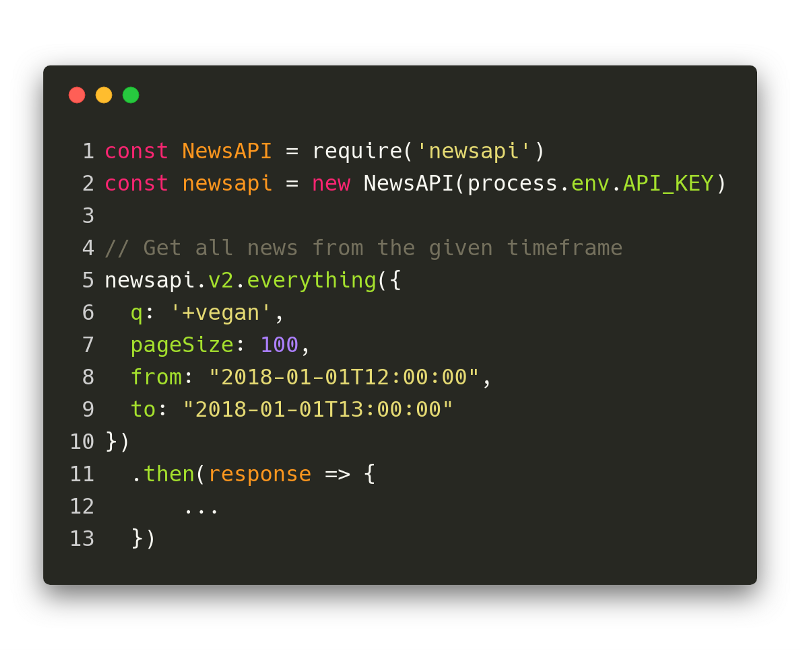 NewsAPI query for 1 hour of data from the beginning of the year
NewsAPI query for 1 hour of data from the beginning of the year
The + sign in front of the query String “vegan” simply means that the word must appear.
The pageSize defines how many articles per request will be returned. You definitely want to keep an eye on that. If, for example, your system has extremely limited memory, it makes sense to do more requests (use the provided cursor) in order to not crash the instance with responses that are too big.
The response from NewsAPI.org looks like this. If you’re interested in seeing more examples, head over to their website where they have a lot of examples displayed.
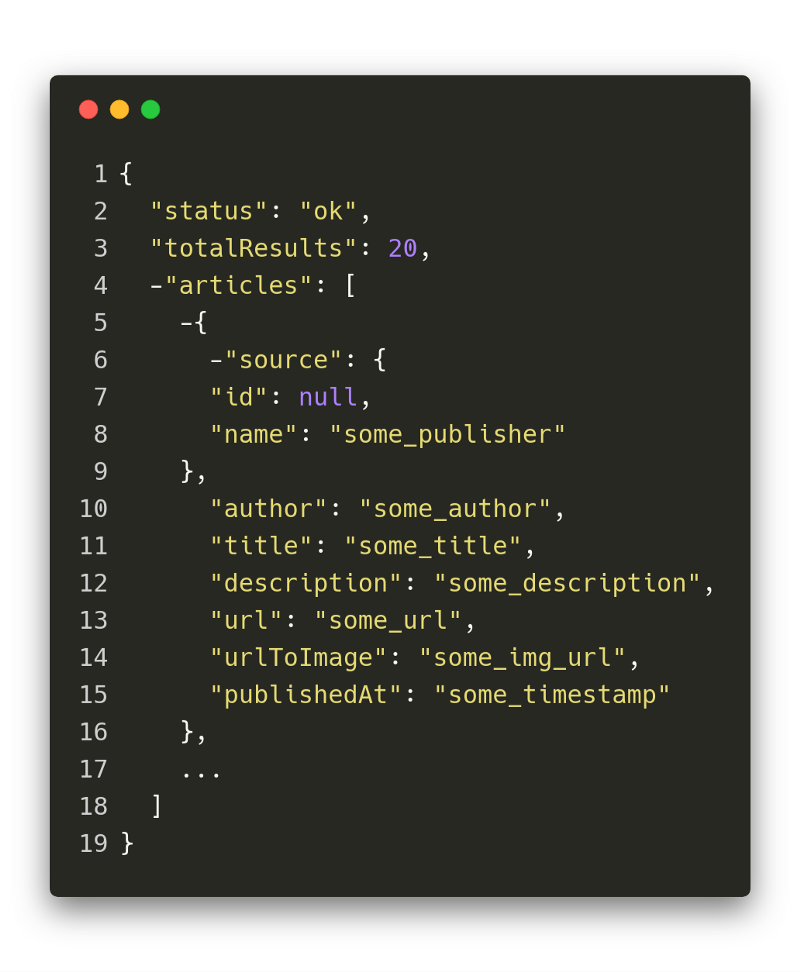
As you can see, those article records only give a very basic view of the article itself. Terms like vegan, which appear in some context inside the article without being the main topic of it, are not represented in the title or description.Therefore, we need the Data Enrichment component, which we’ll cover a little bit later. However, this is exactly the type of JSON data that is stored in the S3 bucket, ready for further processing.
Trying an API locally and actually using it in the cloud are really similar.
Of course, there are some catches where you don’t want to paste your API key into the actual code but rather use environment variables, but that’s about it.
AWS has a very neat GUI for their Lambda setup. It really helps you understand the structure of your component and visualise which services and elements are connected to it.
In the case of the first component, we have the CloudWatch Hourly Trigger on the “Input”-side and the Logging with CloudWatch and the S3 Bucket as a storage system on the “Output”-side.
 Lambda GUI on AWS
Lambda GUI on AWS
So, after putting everything together, importing the Node.JS SDK for AWS, and testing out the whole script locally, I finally deployed it as a Lamdba Function.
The final script is actually pretty short and understandable:
const NewsAPI = require('newsapi')
const moment = require('moment')
const AWS = require('aws-sdk')
exports.handler = async (event) => {
// Right now we only need to query the API every hour because there
// are very few articles that contain the word veganism
const toTS = moment().format('YYYY-MM-DDTHH:mm:ss')
const fromTS = moment(toTS).subtract(1, 'hour').format('YYYY-MM-DDTHH:mm:ss')
const newsapi = new NewsAPI(process.env.API_KEY)
const s3 = new AWS.S3()
const myBucket = process.env.S3_BUCKET
// Get the news from the given timeframe
return new Promise((resolve, reject) => {
newsapi.v2.everything({
q: '+vegan',
pageSize: 100,
from: fromTS,
to: toTS
})
.then(response => {
console.log(`Working with a total of ${response.articles.length} articles.`)
// Write all the documents to the S3-bucket
const promisedArticles = response.articles.map(article => {
const myKey = `sov_${article.publishedAt}.json`
const params = {Bucket: myBucket, Key: myKey, Body: JSON.stringify(article, null, 2)}
// Saving the record for given key in S3
return new Promise((res, rej) => {
s3.putObject(params, (err, data) => {
if (err) {
console.error(`Problem with persisting article to S3... ${err}`)
rej(err)
return
}
console.log(`Successfully uploaded data to ${myBucket}/${myKey}`)
res(`Successfully uploaded data to ${myBucket}/${myKey}`)
})
})
})
})
.catch(err => {
console.error(`Encountered a problem... ${err}`)
reject(err)
})
})
}
view rawsov_article_collection.js hosted with ❤ by GitHub
The GUI has some nice testing features with which you can simply trigger your Function by hand.
But nothing worked…
After a few seconds of googling, I found the term “Policies”. I’d heard of them before, but never read up on them or tried to really understand them.
Basically, they describe what service/user/group is allowed to do what. This was the missing piece: I had to allow my Lambda function to write something to S3. (I won’t go into detail about it here, but if you want to skip to policies, feel free to head to the end of the article.)
A policy in AWS is a simple JSON-Style configuration which, in the case of my article collection function, looked like this:
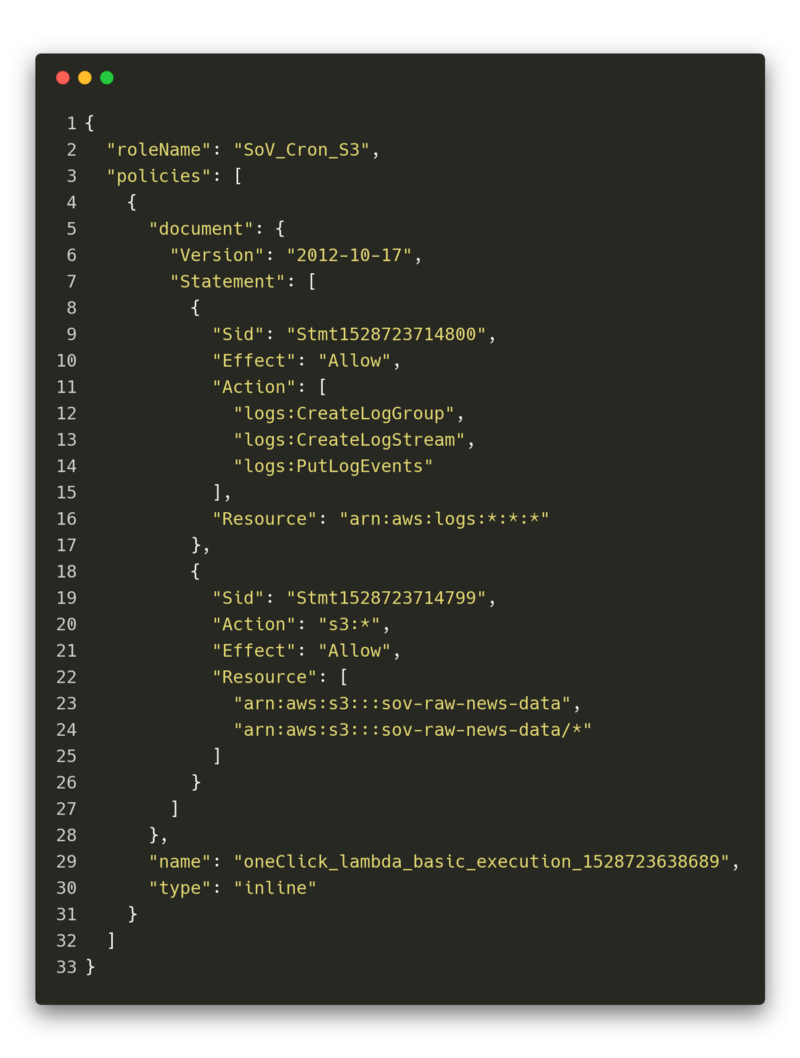
This is the config that describes the previously mentioned “Output”-Side of the function. In the statements, we can see that it gets access to different methods of the logging tools and S3.
The weird part about the assigned resource for the S3 bucket is that, if not stated otherwise in the options of your S3 bucket, you have to both provide the root and “everything below” as two separate resources.
The example given above allows the Lambda Function to do anything with the S3 bucket, but this is not how you should set up your system! Your components should only be allowed to do what they are designated to.
Once this was entered, I could finally see the records getting put into my S3 bucket.

Special Characters are evil…
When I tried to get the data back from the S3 bucket I encountered some problems. It just wouldn’t give me the JSON file for the key that was created.
I had a hard time finding out what was wrong until at one point, I realised that, by default, AWS enables logging for your services.
This was gold!
When I looked into the logs, the problem jumped out at me right away: it seemed like the key-value that gets sent by the S3-Trigger does some URL-Encoding. However, this problem was absolutely invisible when just looking at the S3 key names where everything was displayed correctly.
![]()
The solution to this problem was pretty easy. I just replaced every special character with a dash which won’t be replaced by some encoded value.
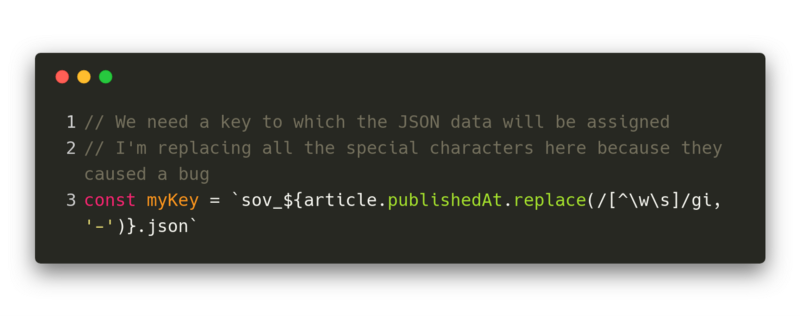 Solution to the URLEncoded key problem
Solution to the URLEncoded key problem
So, always make sure to not risk putting some special characters in keys. It might save you a ton of debugging and effort.
![]()
Data Enrichment
 Data Enrichment Part
Data Enrichment Part
Since we now have all the articles as single records in our S3 bucket, we can think about enrichment. We have to combine some steps in order to fulfill our pipeline which, just to think back, was the following:
- Get record from S3 bucket.
- Build a context from the actual article in combination with the title and description.
- Analyse the created context and enrich the record with the result.
- Write the enriched article-record to our DynamoDB table.
One of the really awesome things about Promises in JavaScript is that you can model pipelines exactly the way you would describe them in text. If we compare the code with the explanation of what steps will be taken, we can see the similarity.
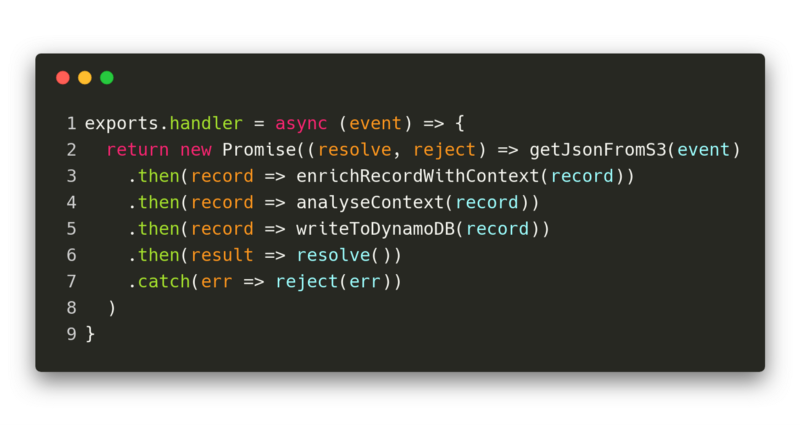
If you take a closer look at the first line of the code above, you can see the export handler. This line is always predefined in the Lambda Functions in order to know which method to call. This means that your own code belongs in the curly braces of the async block.
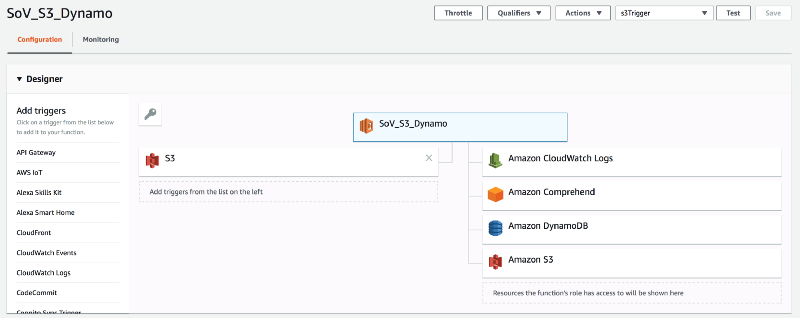
For the Data Enrichment part, we need some more services. We want to be able to send and get data from Comprehends sentiment analysis, write our final record to DynamoDB, and also have logging.
Have you noticed the S3 Service on the “Output”-side? This is why I always put the Output in quotes, even though we only want to read data here. It’s displayed on the right hand side. I basically just list all the services our function interacts with.
The policy looks comparable to the one of the article collection component. It just has some more resources and rules which define the relation between Lambda and the other services.
Even though Google Cloud, in my opinion, has the “better” NLU components, I just love the simplicity and unified API of AWS’ services. If you’ve used one of them, you think you know them all. For example, here’s how to get a record from S3 and how the sentiment detection works in Node.js:
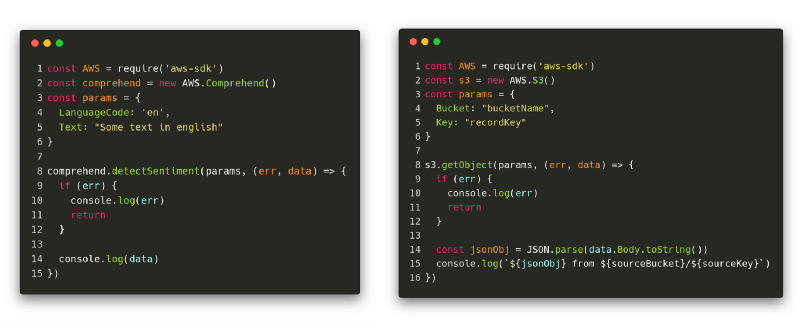
Probably one of the most interesting tasks of the Data Enrichment Component was the creation of the “context” of the word vegan in the article.
Just as a reminder — we need this context, since a lot of articles only mention the word “Vegan” without having “Veganism” as a topic.
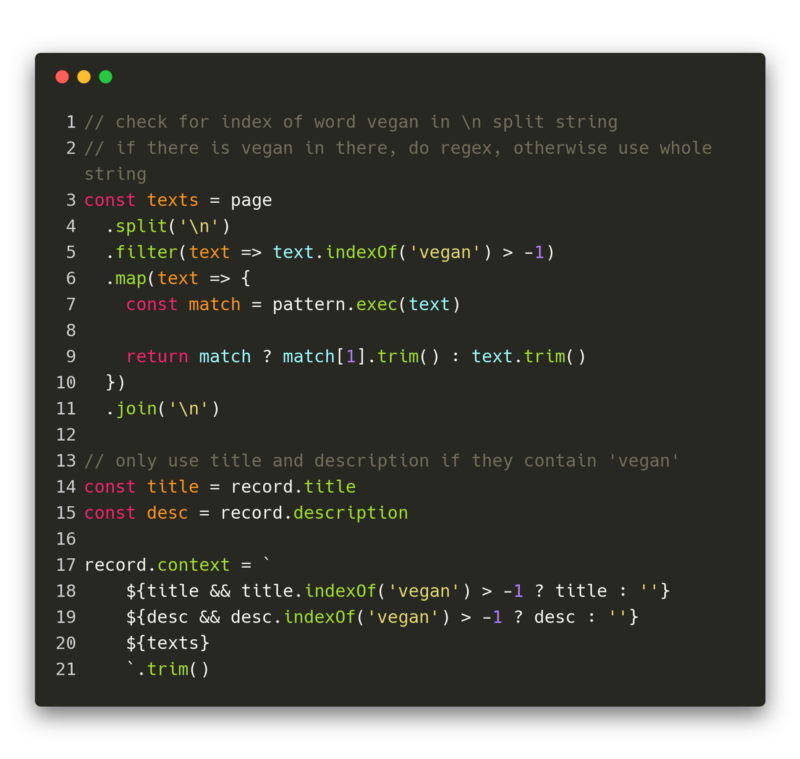
So, how do we extract parts from a text? I went for Regular Expressions. They are incredibly nice to use, and you can use playgrounds like Regex101 to play around and find the right regex for your use case.
The challenge was to come up with a regex that could find sentences that contained the word “vegan”. Somehow it was harder than I expected to make it generalise for whole text passages that also had line breaks and so on in them.
The final regex looks like this:

The problem was that for long texts, this was not working due to timeout problems. The solution in this case was pretty “straightforward”… I simply crawled the text and split it by line breaks, which made it way easier to process for the RegEx module.
In the end, the whole context “creation” was a mixture of splitting the text, filtering for passages that contained the word vegan, extracting the matching sentence from that passage, and joining it back together so that it could be used in the sentiment analysis.
Also the title and description might play a role, so I added those to the context if they contained the word “vegan”.
Once all the code for the different steps was in place, I thought I could start building the frontend. But something wasn’t right. Some of the records just did not appear in my DynamoDB table…
Empty Strings in DynamoDB are also evil
When checking back with the status of my already running system, I realised that some of the articles would not be converted to a DynamoDB table entry at all.
After checking out the logs, I found this Exception which absolutely confused me…
![]()
To be honest, this was a really weird behaviour since, as stated in the discussion, the semantics and usage of an empty String are absolutely different than that of a Null value.
However, since I couldn’t change anything about the design of the DynamoDB, I had to find a solution to avoid getting the empty String error.
In my case, it was really easy. I just iterated through the whole JSON object and checked whether there was an empty String or not. If there was, I just replaced the value with null. That’s it, works like charm and does not cause any problems. (I needed to check if it has a value in the frontend, though, since getting the length of a null value throws an error).
 “Dirty” Fix for the empty String problem
“Dirty” Fix for the empty String problem
Frontend
 Frontend Part
Frontend Part
The last part was to actually create a frontend and deploy it so people could visit the page and see the StateOfVeganism.
Of course, I was thinking about whether I should use one of those fancy frontend frameworks like Angular, React or Vue.js… But, well, I went for absolutely old school, plain HTML, CSS and JavaScript.
The idea I had for the frontend was extremely minimalistic. Basically it was just a bar that was divided into three sections: Positive, Neutral and Negative. When clicking on either one of those, it would display some titles and links to articles that were classified with this sentiment.
In the end, that was exactly what it turned out to be. You can check out the page here. I thought about making it live at stateOfVeganism.com, but we’ll see…
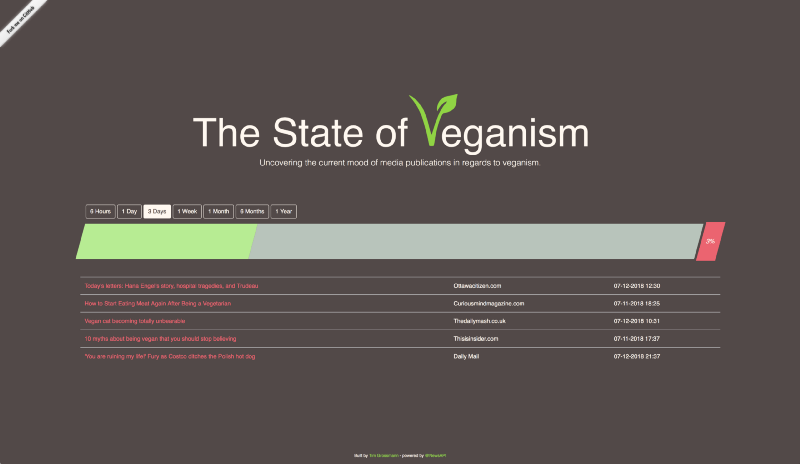 GUI of StateOfVegnsim
GUI of StateOfVegnsim
Make sure to note the funny third article of the articles that have been classified as “Negative” ;)
Deploying the frontend on one of AWS’ services was something else I had to think about. I definitely wanted to take a service that already incorporated elastic scaling, so I had to decide between Elastic Container Service or Elastic Beanstalk (actual EC2 instances).
In the end, I went for Beanstalk, since I really liked the straightforward approach and the incredibly easy deployment. You can basically compare it to Heroku in the way you set it up.
Side note: I had some problems with my auto scaling group not being allowed to deploy EC2 instances, because I use the free tier on AWS. But after a few emails with AWS support, everything worked right out of the box.
I just deployed a Node.js Express Server Application that serves my frontend on each path.

This setup, by default, provides the index.html which resides in the “public” folder, which is exactly what I wanted.
Of course this is the most basic setup. For most applications, it’s not the recommended way, since you somehow have to provide the credentials in order to access the DynamoDB table. It would be better to do some server-side rendering and store the credentials in environment variables so that nobody can access them.
Playing it cool and deploying the AWS keys in the front end
This is something you should never do. However, since I restricted the access of those credentials to only the scan method of the DynamoDB table, you can get the chance to dig deeper into my data if you’re interested.
I also restricted the number of requests that can be done, so that the credentials will “stop working” once the free monthly limit has been surpassed, just to make sure.
But feel free to look at the data and play around a little bit if you’re interested. Just make sure to not overdo it, since the API will stop providing the data to the frontend at some point.
Policies, Policies?… Policies!
When I started working with cloud technologies, I realised that there has to be a way to allow/restrict access to the single components and create relations. This is where policies come into place. They also help you do access management by giving you the tools you need to give specific users and groups permissions. At one point, you’ll probably struggle with this topic, so it makes sense to read up on it a little bit.
There are basically two types of policies in AWS. Both are simple JSON style configuration files. However, one of them is assigned to the resource itself, for example S3, and the other one gets assigned to roles, users, or groups.
The table below shows some very rough statements about which policy you might want to choose for your task.
So, what is the actual difference? This might become clearer when we compare examples of both policy types.
 IAM-Policy and Resource Policy
IAM-Policy and Resource Policy
The policy on the left is the IAM-Policy (or Identity-Based). The right one is the Resource-(Based)-Policy.
If we start to compare them line by line, we can’t see any difference until we reach the first statement which defines some rules related to some service. In this case, it’s S3.
In the Resource-Policy, we see an attribute that is called “Principal” which is missing in the IAM-Policy. In the context of a Resource-Policy, this describes the entities that are “assigned” to this rule. In the example given above, this would be the users, Alice and root.
On the other hand, to achieve the exact same result with IAM-Policies, we would have to assign the policy on the left to our existing users, Alice and root.
Depending on your use case, it might make sense to use one or the other. It’s also a question of what your “style” or the convention or your workplace is.
What’s next?
StateOfVeganism is live already. However, this does not mean that there is nothing to improve. One thing I definitely have to work on is, for example, that recipes from Pinterest are not classified as “Positive” but rather “Neutral”. But the basic functionality is working as expected. The data pipeline works nicely, and if anything should go wrong, I will have nice logging with CloudWatch already enabled.
It’s been great to really think through and build such a system. Questioning my decisions was very helpful in optimising the whole architecture.
The next time you’re thinking about building a side project, think about building it with one of the cloud providers. It might be a bigger time investment in the beginning, but learning how to use and build systems with an infrastructure like AWS really helps you to grow as a developer.
I’d love to hear about your projects and what you build. Reach out and tell me about them.
Thank you for reading. Be sure to follow me on YouTube and to star StateOfVeganism on GitHub.
Don’t forget to hit the clap button and follow me on Twitter, GitHub, Youtube, and Facebook to follow me on my journey.
I’m always looking for new opportunities.
So please, feel free to contact me. I’d love to get in touch with you.
Also, I’m currently planning to do a half year internship in Singapore starting in March 2019. I’d like to meet as many of you as possible. If you live in Singapore, please reach out. Would love to have a chat over coffee or lunch.