
By Simone Di Maulo
An overview of different app design options
When we design software, we constantly think about error cases. Errors have a huge impact on the way we design and architecture a solution. So much so, in fact, that there is a philosophy known as Let It Crash.
Let it crash is the Erlang way to treat failures by just letting the application crash and allowing a supervisor to restart the crashed process from a clean state.
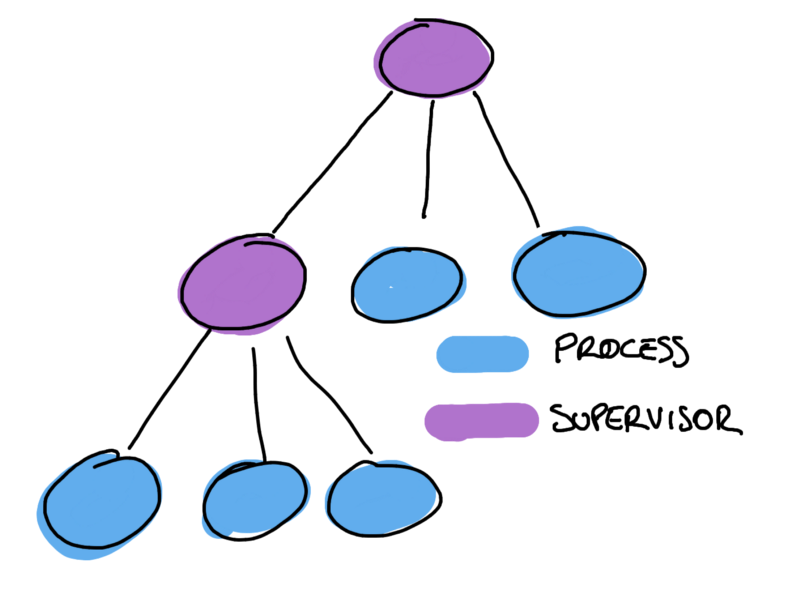 Supervisors restart the crashed process
Supervisors restart the crashed process
Errors could be everywhere, and the more your application grows, the more there will be points of failure that you need to keep under control. External service calls, sending email, database queries are all operations that could fail.
Kinds of Failures
A failure can have different origins which lead to different impacts on your service availability. Think of a scenario where we’re running too many SQL queries and the database server is going to throttle the application. In that case, we could retry the query or add a catch in the code to identify the failing queries and provide a sensible response to the user.
These kinds of errors are called Transient Errors, which means that the database server is temporary overloaded but it’s going to come back soon.
Transient errors are not related to any problem in the application. They are usually caused by external conditions such as network failures, overloaded servers, or service rate limits. For that reason, it’s safe for a client to ignore it and retry the failed operation after a while.
These errors are much more frequent within cloud native applications, because the apps are split into different services and deployed on different servers that communicate over the network.
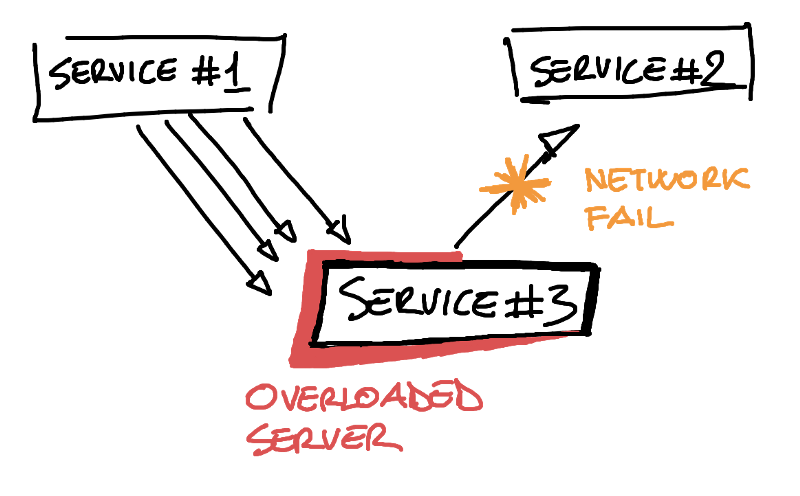
Identifying Transient Errors
Transient errors can usually be detected in an automatic manner.
We can recognise the errors by inspecting the transport layer metadata (for example HTTP errors, network errors, timeouts) or when they are explicitly marked as transient (such as rate limits).
Treating the Errors
There are different actions we can do in case of an error. One trivial approach could be to just retry the request, API call, or query.
Even though this solution might be fine in many cases, there are lot of cases when it can lead to a performance decrease for the app.
Let’s take the case of a network failure. Indefinitely retrying some API calls to a disconnected service would result in continuous network timeouts, and the application will be stuck waiting for a response for a very long time.
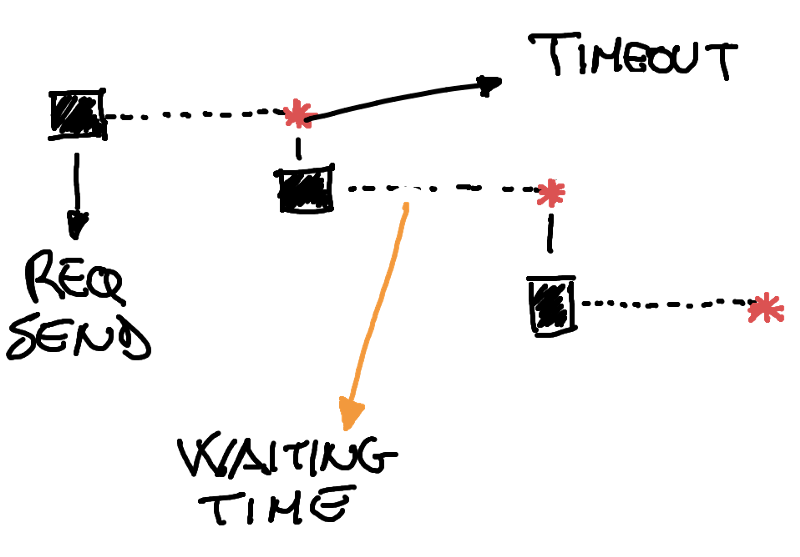
Before going ahead with complex implementations, let’s evaluate the pros and cons of the “just-retry” option.
PROS
- Trivial implementation.
- Stateless (every retry request is isolated and you don’t need any extra information).
CONS
- For heavily loaded applications, the caller will continuously send requests to the degraded server resulting in a denial of service.
- Cannot provide a response until the server comes back.
This simple retry strategy can be considered as a very first approach to solving the issue. For low traffic apps it would work, but if you have a more complex architecture, it’s definitely not enough.
So let’s discuss a more resilient approach.
Stealing an Idea from the IEEE
The next stop of your journey for a reliable application is to avoid the wasted time and to make the application more responsive. The exponential backoff algorithm could be the right tool for the job.
The concept of the exponential backoff directly comes from the Ethernet network protocol (IEEE 802.3) where it’s used for packet collision resolution.
For our purposes, the exponential backoff can be used to avoid wasting time between timed out calls or to avoid hammering an overloaded server with an continual flow of requests that cannot be resolved.
Binary exponential backoff for packet collisions can be resumed with help from the follow definition:
After c collisions, a random number of slot times between 0 and 2c - 1 is chosen. For the first collision, each sender will wait 0 or 1 slot times. After the second collision, the senders will wait anywhere from 0 to 3 slot times. After the third collision, the senders will wait anywhere from 0 to 7 slot times (inclusive), and so forth. As the number of retransmission attempts increases, the number of possibilities for delay increases exponentially - Exponential backoff - Wikipedia

This algorithm can be quickly adapted to many use cases. The following example is a PHP message handler class that exponentially waits for a response from an API endpoint.
<?php
/**
* Assume that we're using a message bus which is able to
* retry failed messages with a custom retry delay.
*/
class FetchCarMessageHandler
{
public function handle(Message $msg)
{
try {
$id = (int)$msg->getContent();
$cars = $client->get('/car/'.$id);
return Result::success($cars);
} catch (TimeoutException $e) {
$lastBackoff = $msg->getLastBackoff();
// The infrastructure layer will automagically retry the message after XYZ seconds
return Result::retryAfter($lastBackoff * 2, $msg);
}
}
}
Retry vs Exponential Backoff
The previous two strategies are both sub-optimal. They guarantee that you’ll eventually be able to generate a response to give back to the client, but they rely on continuously calling the external service until a successful response is received.
We may be lucky and receive a response after a couple of retries, or we could fall in the retry-wait-retry-wait… infinite loop and never receive the response.
You know, Murphy’s law is always here: “Anything that can go wrong will go wrong.”
As you might imagine, scaling a service oriented infrastructure that in case of failure continuously retries the request to the dependant services is the perfect recipe for application collapse.
We need a stronger strategy to maintain infrastructure resilience.
Electronics may Help Us
 _[Source: https://pixabay.com/en/circuit-breakers-rcds-fault-current-1167327/](https://pixabay.com/en/circuit-breakers-rcds-fault-current-1167327/" rel="noopener" target="blank" title=")
_[Source: https://pixabay.com/en/circuit-breakers-rcds-fault-current-1167327/](https://pixabay.com/en/circuit-breakers-rcds-fault-current-1167327/" rel="noopener" target="blank" title=")
In case of continuous errors, the easy thing to do is clear. We do not want to loop and retry calling an external service. The point is we’ll just stop doing it, by taking the concept of Circuit Breakers from electronics.
From Electronics to Computer Science
A circuit breaker is a component that wraps a protected call to an external service and can monitor the responses by checking the service health. Exactly like an electronic component, a software circuit breaker could be open or closed. An open status would mean that the service behind the circuit is down, and a closed status would mean that the service is up.
So the circuit breaker can autonomously control the service status and decide to open or close the circuit, so that in case of disconnection or server overload, the client stops sending new connections and the degraded service can use more resources to come back to a healthy state.
In case of an open circuit, we could decide to quickly answer to the client with a fallback response. For example, cached data, default data, or whatever make sense for the particular application.
Let’s see a real example from the e-commerce world. We’re going to use the circuit breaker method to protect the product listing API call.
<?php
class CircuitBreaker
{
private $maxFailures;
private $service;
private $redisClient;
public function __construct(int $maxFailures, callable $service)
{
$this->maxFailures = $maxFailures;
$this->service = $service;
$this->redisClient = new RedisClient();
}
private function isUp(string $key)
{
return (int)$this->redisClient->get($key) < $this->maxFailures;
}
private function fail(string $key, int $ttl)
{
$this->redisClient->incr($key, 1);
$this->redisClient->expire($key, $ttl);
}
public function __invoke()
{
[$arguments, $defaultResponse] = func_get_args();
$key = md5($arguments);
if (!$this->isUp($key)) {
return $defaultResponse;
}
try {
$result = call_user_func_array($this->service, $arguments);
return $result;
} catch (\Throwable $e) {
$this->fail($key, 10);
return $defaultResponse;
}
}
}
The circuit breaker will transparently handle all errors and show the default response in case of an API call failure. It also allows defining a max number of retries to avoid too many failed calls.
In this case, protecting a third party service API call is a very simple task: we just need to provide the callback and number of max failures allowed, after which the circuit breaker will be opened for 10 seconds and the default response is given back to the client, as in the example below.
<?php
$productListing = new CircuitBreaker(
10,
function($searchKey) {
// $result is given from the api call
return $result;
}
);
$productsToShow = $productListing(['t-shirt'], []);
Conclusion
Whether you’re designing a SOA, micro services or a cloud native application, you should be ready to tackle the failure case in the right way. Errors and failures are in the same room from the day you launch your app.
Here some of the well known tactics to build a real rock solid app: