

spaCy is an open-source software library for advanced natural language processing. It's written in the programming languages Python and Cython, and is published under the MIT license.
spaCy excels at large-scale information extraction tasks. It's written from the ground up in carefully memory-managed Cython.
spaCy is designed to help us build real products, or gather real insights. It's built with 73+ languages, and supports custom models built with Pytorch and Tensorflow. It's robust and has rigorously evaluated accuracy.
You may not know much about Cython. So let's have a quick look at it.
What is Cython?
Cython is a Python compiler that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports more cutting edge functionality and optimizations.
To put in simple words, it's a Python to C compiler.
Quoting from Wikipedia,
Cython is a programming language, a superset of the Python programming language, designed to give C-like performance with code that is written mostly in Python with optional additional C-inspired syntax.
So you might be wondering if you need to learn Cython to help you fine-tune your spaCy models.
Well, don't worry. You don't need to learn Cython to to work with spaCy. I just wanted to make sure you're aware of what it is to help you get the most out of this tutorial.
Prerequisites
Basic knowledge of spaCy
The official documentation site of spaCy provides a lot of information about the tool. Alternatively, you can read my other tutorial which gives some basic information about spaCy.
Basic knowledge of how to gather data
In order to fine-tune any model, you need to have the data ready. And it should be good quality data.
In this tutorial, let's assume we've built a event management software. We want to add voice assistance to our software. We have a module that converts voice input into text. Our next step is to process this text and extract data from the given sentence using spaCy.
We have to gather some basic sentences that we hear from people trying to schedule a event. Here are a few examples:
- Schedule event for visit to Trivandrum on July 18
- Create event happening tomorrow on AI
- Schedule Pongal celebration event in Oaks HOA at June 20, 2023
Similarly, we have to collect prompts related to event scheduling. The more data you collect and input, more accurate your model will be.
I created 7 sentences, which is much too small for a event management software company to train its model. But from a demo standpoint, it should be enough.
How to Pre-Process the Data
Collecting data covers just one part of the equation. We need to pre-process the data and transform it in a way that spaCy can easily understand. We should also define what kind of data (tags) should be identified from the given sentences.
Let's take the following sentence as an example:
"Schedule event for visit to Trivandrum on July 18".
Let's try to split out some tags from above sentence:
- Schedule – this belongs to the "action" tag
- event – this belongs to the "domain" tag
- visit to Trivandrum – this belongs to the "name" tag
- July 18 – this belongs to the "date" tag
Every tag defined above may contain alternatives in other sentences. For an example, we may input the following sentences:
- Cancel client meeting scheduled tomorrow
- Change time of mall visit to 6 PM
From the above sentences, the action tags are "Cancel" and "Change". Similarly data for each tag may vary for each sentence.
Our next step is to teach spaCy about the words for each tag. We need to prepare a JSON file that contains examples with the tags and their indices.
For example, in the above sentence ("Schedule event for visit to Trivandrum on July 18"), the index for the "action" tag starts from 0 (indices always start from 0 in Python) and ends at 7.
Similarly for all 7 sentences I've chosen, I've prepared the index for each tag and created the JSON file.
How to Fine-Tune the spaCy Model
Let's try to fine-tune spaCy with the data that we have.
Create a folder and download the above JSON file and place it into the folder. Create a new file named custom_model.ipynb.
All the following sections below need a code block to be created. Create a code block wherever you see a heading. Here's a sample screenshot.
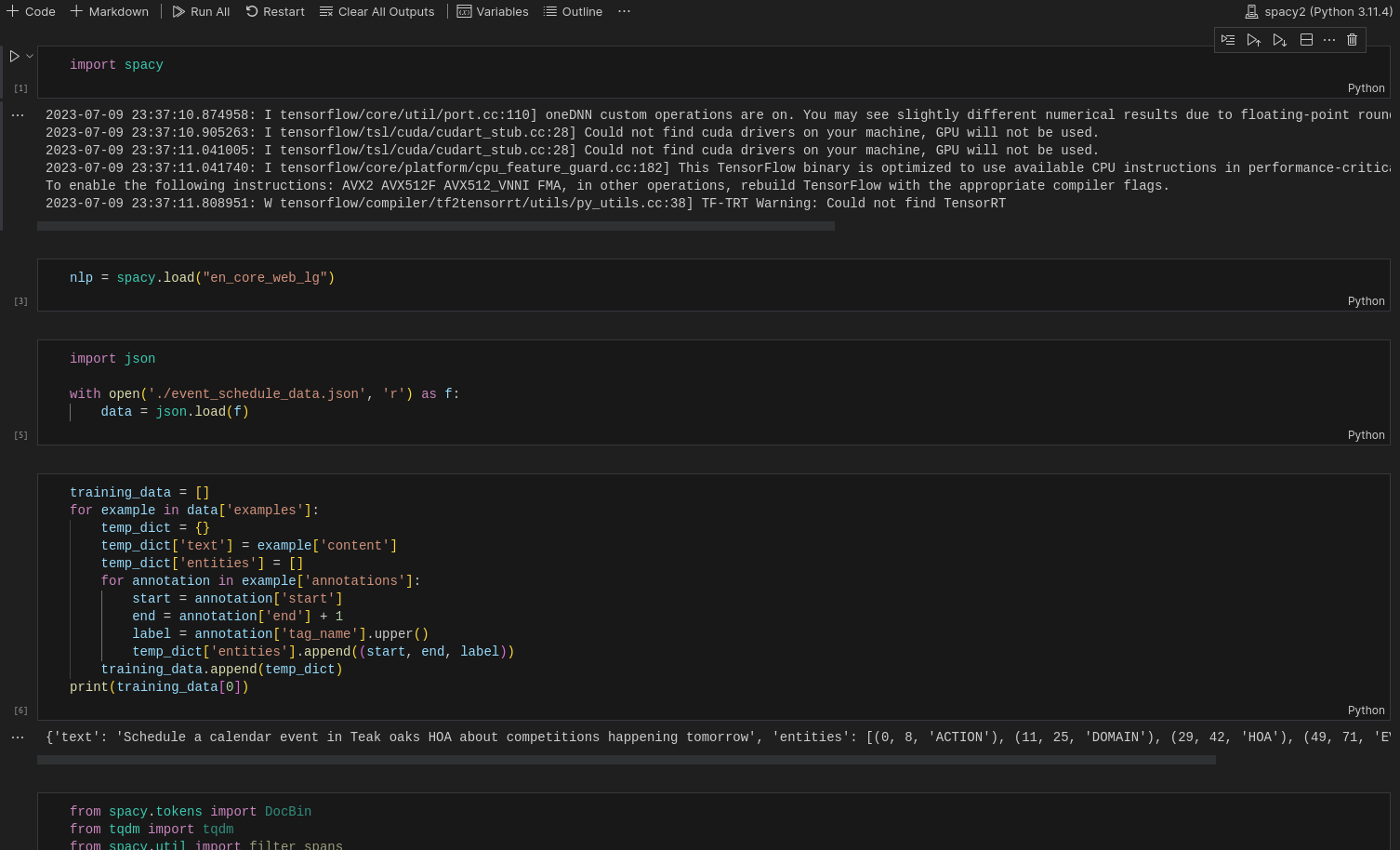 Creating and running blocks of code
Creating and running blocks of code
Import spaCy
import spacy
Load the pre-trained model
nlp = spacy.load("en_core_web_lg")
Import the JSON file
Import the above downloaded JSON file.
import json
with open('./event_schedule_data.json', 'r') as f:
data = json.load(f)
Convert the data
Convert the data read from JSON file into tuple of dictionaries containing original text and entities.
training_data = []
for example in data['examples']:
temp_dict = {}
temp_dict['text'] = example['content']
temp_dict['entities'] = []
for annotation in example['annotations']:
start = annotation['start']
end = annotation['end'] + 1
label = annotation['tag_name'].upper()
temp_dict['entities'].append((start, end, label))
training_data.append(temp_dict)
print(training_data[0])
The above code will convert the data to the required format and print the first dictionary in the tuple, which will look something like below:
{'text': 'Schedule a calendar event in Teak oaks HOA about competitions happening tomorrow', 'entities': [(0, 8, 'ACTION'), (11, 25, 'DOMAIN'), (29, 42, 'HOA'), (49, 71, 'EVENT'), (72, 80, 'DATE')]}
Import training libraries
from spacy.tokens import DocBin
from tqdm import tqdm
from spacy.util import filter_spans
nlp = spacy.blank('en')
Train the model
The below code will create a custom model with the data that we give. A binary file named train.spacy will be generated at the end.
doc_bin = DocBin()
for training_example in tqdm(training_data):
text = training_example['text']
labels = training_example['entities']
doc = nlp.make_doc(text)
ents = []
for start, end, label in labels:
span = doc.char_span(start, end, label=label, alignment_mode="contract")
if span is None:
print("Skipping entity")
else:
ents.append(span)
filtered_ents = filter_spans(ents)
doc.ents = filtered_ents
doc_bin.add(doc)
doc_bin.to_disk("train.spacy")
Create config files
Create a new file named base_config.cfg and copy the below code into it.
Create another file named config.cfg and copy the below code into it.
Don't worry. These are default configurations that I've taken from their official documentation and I've not made any changes to it.
Initialize spaCy with the config files
Run the following command in the notebook code block to initialize spaCy with the config file. This config file will be used to train the spaCy model with our generated custom model.
!python -m spacy init fill-config base_config.cfg config.cfg
Train spaCy model
Run the following command to train the spaCy model:
!python -m spacy train config.cfg --output ./ --paths.train ./train.spacy --paths.dev ./train.spacy
This may take some time depending on your system configuration. Ideally not too long (around 5 to 10 minutes). At the end, it'll generate 2 folders named model-best and model-last.
Load the best model
nlp_ner = spacy.load("model-best")
Test our model
Let's test our model with the following input.
"Could you please reserve a team brainstorming session on coming Wednesday at 11 AM?"
doc = nlp_ner("Could you please reserve a team brainstorming session on coming Wednesday at 11 AM?")
spacy.displacy.render(doc, style="ent")
You should be surprised to see the output.
 Entity representation of our input sentence
Entity representation of our input sentence
That's great right?
Eventually, you may have a question: as a programmer, how can I get this data in my backend code?
Well, that's something everyone asks.
spaCy has an answer for it. You can expose the above data as JSON.
Convert extracted data to JSON
json_obj = doc.to_json()
json_obj
This will show a similar output like the one below.
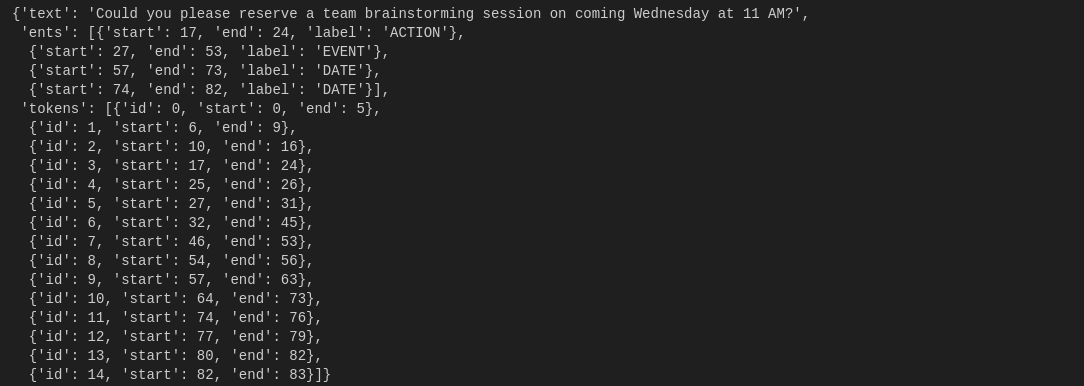 JSON of our test sentence input
JSON of our test sentence input
Write a REST API and expose this data as JSON. That's it. But remember, spaCy will give you only the indices, you have parse your sentence and extract words in between those indices.
Conclusion
In this article, we learnt about how to customize and fine-tune a pre-trained spaCy model with the data that corresponds to our domain knowledge.
Similarly you can also train with your domain specific data. The model that you fine-tune will be private to you unless you expose it to the public. So it's best suited for training with the domain data that is not publicly available.
If you wish to learn more about NLP/Machine Learning, subscribe to my email newsletter (https://5minslearn.gogosoon.com/) and follow me on social media.