
By dor sever
My last task at BigPanda was to upgrade an existing service that was using Elasticsearch version 1.7 to a newer Elasticsearch version, 6.8.1.
In this post, I will share how we migrated from Elasticsearch 1.6 to 6.8 with harsh constraints like zero downtime, no data loss, and zero bugs. I'll also provide you with a script that does the migration for you.
This post contains 6 chapters (and one is optional):
- What’s in it for me? --> What were the new features that led us to upgrade our version?
- The constraints --> What were our business requirements?
- Problem solving --> How did we address the constraints?
- Moving forward --> The plan.
- [Optional chapter] --> How did we handle the infamous mapping explosion problem?
- Finally --> How to do data migration between clusters.
Chapter 1 — What’s in it for me?
What benefits were we expecting to solve by upgrading our data store?
There were a couple of reasons:
- Performance and stability issues — We were experiencing a huge number of outages with long MTTR that caused us a lot of headaches. This was reflected in frequent high latencies, high CPU usage, and more issues.
- Non-existent support in old Elasticsearch versions — We were missing some operative knowledge in Elasticsearch, and when we searched for outside consulting we were encouraged to migrate forward to receive support.
- Dynamic mappings in our schema — Our current schema in Elasticsearch 1.7 used a feature called dynamic mappings that made our cluster explode multiple times. So we wanted to address this issue.
- Poor visibility on our existing cluster — We wanted a better view under the hood and saw that later versions had great metrics exporting tools.
Chapter 2 — The constraints
- ZERO downtime migration — We have active users on our system, and we could not afford for the system to be down while we were migrating.
- Recovery plan — We could not afford to “lose” or “corrupt” data, no matter the cost. So we needed to prepare a recovery plan in case our migration failed.
- Zero bugs — We could not change existing search functionality for end-users.
Chapter 3 — Problem solving and thinking of a plan
Let’s tackle the constraints from the simplest to the most difficult:
Zero bugs
In order to address this requirement, I studied all the possible requests the service receives and what its outputs were. Then I added unit-tests where needed.
In addition, I added multiple metrics (to the Elasticsearch Indexer and the new Elasticsearch Indexer ) to track latency, throughput, and performance, which allowed me to validate that we only improved them.
Recovery plan
This means that I needed to address the following situation: I deployed the new code to production and stuff was not working as expected. What can I do about it then
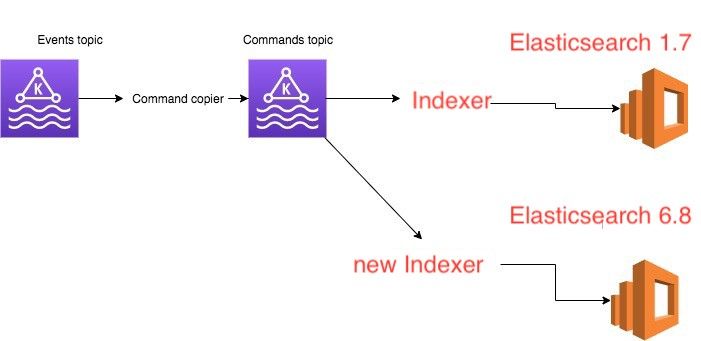
Since I was working in a service that used event-sourcing, I could add another listener (diagram attached below) and start writing to a new Elasticsearch cluster without affecting production status
Zero downtime migration
The current service is in live mode and cannot be “deactivated” for periods longer than 5–10 minutes. The trick to getting this right is this:
- Store a log of all the actions your service is handling (we use Kafka in production)
- Start the migration process offline (and keep track of the offset before you started the migration)
- When the migration ends, start the new service against the log with the recorded offset and catch up the lag
- When the lag finishes, change your frontend to query against the new service and you are done
Chapter 4 — The plan
Our current service uses the following architecture (based on message passing in Kafka):
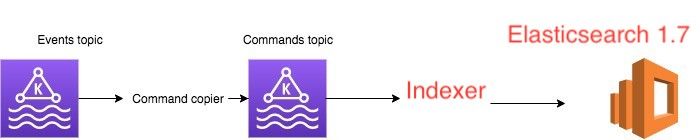
Event topiccontains events produced by other applications (for example,UserId 3 created)Command topiccontains the translation of these events into specific commands used by this application (for example:Add userId 3)- Elasticsearch 1.7 — The datastore of the
command Topicread by theElasticsearch Indexer.
We planned to add another consumer (new Elasticsearch Indexer) to the command topic, which will read the same exact messages and write them in parallel to Elasticsearch 6.8.
Where should I start?
To be honest, I considered myself a newbie Elasticsearch user. To feel confident to perform this task, I had to think about the best way to approach this topic and learn it. A few things that helped were:
- Documentation — It’s an insanely useful resource for everything Elasticsearch. Take the time to read it and take notes (don’t miss: Mapping and QueryDsl).
- HTTP API — everything under CAT API. This was super useful to debug things locally and see how Elasticsearch responds (don’t miss: cluster health, cat indices, search, delete index).
- Metrics (❤️) — From the first day, we configured a shiny new dashboard with lots of cool metrics (taken from elasticsearch-exporter-for-Prometheus) that helped and pushed us to understand more about Elasticsearch.
The code
Our codebase was using a library called elastic4s and was using the oldest release available in the library — a really good reason to migrate! So the first thing to do was just to migrate versions and see what broke.
There are a few tactics on how to do this code migration. The tactic we chose was to try and restore existing functionality first in the new Elasticsearch version without re-writing the all code from the start. In other words, to reach existing functionality but on a newer version of Elasticsearch.
Luckily for us, the code already contained almost full testing coverage so our task was much much simpler, and that took around 2 weeks of development time.

It's important to note that, if that wasn't the case, we would have had to invest some time in filling that coverage up. Only then would we be able to migrate since one of our constraints was to not break existing functionality.
Chapter 5 — The mapping explosion problem
Let’s describe our use-case in more detail. This is our model:
class InsertMessageCommand(tags: Map[String,String])
And for example, an instance of this message would be:
new InsertMessageCommand(Map("name"->"dor","lastName"->"sever"))
And given this model, we needed to support the following query requirements:
- Query by value
- Query by tag name and value
The way this was modeled in our Elasticsearch 1.7 schema was using a dynamic template schema (since the tag keys are dynamic, and cannot be modeled in advanced).
The dynamic template caused us multiple outages due to the mapping explosion problem, and the schema looked like this:
curl -X PUT "localhost:9200/_template/my_template?pretty" -H 'Content-Type: application/json' -d '
{
"index_patterns": [
"your-index-names*"
],
"mappings": {
"_doc": {
"dynamic_templates": [
{
"tags": {
"mapping": {
"type": "text"
},
"path_match": "actions.tags.*"
}
}
]
}
},
"aliases": {}
}'
curl -X PUT "localhost:9200/your-index-names-1/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "John",
"lname" : "Smith"
}
}
}
'
curl -X PUT "localhost:9200/your-index-names-1/_doc/2?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "Dor",
"lname" : "Sever"
}
}
}
'
curl -X PUT "localhost:9200/your-index-names-1/_doc/3?pretty" -H 'Content-Type: application/json' -d'
{
"actions": {
"tags" : {
"name": "AnotherName",
"lname" : "AnotherLastName"
}
}
}
'
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match" : {
"actions.tags.name" : {
"query" : "John"
}
}
}
}
'
# returns 1 match(doc 1)
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"match" : {
"actions.tags.lname" : {
"query" : "John"
}
}
}
}
'
# returns zero matches
# search by value
curl -X GET "localhost:9200/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"query_string" : {
"fields": ["actions.tags.*" ],
"query" : "Dor"
}
}
}
'
Nested documents solution
Our first instinct in solving the mapping explosion problem was to use nested documents.
We read the nested data type tutorial in the Elastic docs and defined the following schema and queries:
curl -X PUT "localhost:9200/my_index?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"tags": {
"type": "nested"
}
}
}
}
}
'
curl -X PUT "localhost:9200/my_index/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"tags" : [
{
"key" : "John",
"value" : "Smith"
},
{
"key" : "Alice",
"value" : "White"
}
]
}
'
# Query by tag key and value
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "tags",
"query": {
"bool": {
"must": [
{ "match": { "tags.key": "Alice" }},
{ "match": { "tags.value": "White" }}
]
}
}
}
}
}
'
# Returns 1 document
curl -X GET "localhost:9200/my_index/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "tags",
"query": {
"bool": {
"must": [
{ "match": { "tags.value": "Smith" }}
]
}
}
}
}
}
'
# Query by tag value
# Returns 1 result
And this solution worked. However, when we tried to insert real customer data we saw that the number of documents in our index increased by around 500 times.
We thought about the following problems and went on to find a better solution:
- The amount of documents we had in our cluster was around 500 million documents. This meant that, with the new schema, we were going to reach two hundred fifty billion documents (that’s 250,000,000,000 documents ?).
- We read this really good blog post — https://blog.gojekengineering.com/elasticsearch-the-trouble-with-nested-documents-e97b33b46194 which highlights that nested documents can cause high latency in queries and heap usage problems.
- Testing — Since we were converting 1 document in the old cluster to an unknown number of documents in the new cluster, it would be much harder to track if the migration process worked without any data loss. If our conversion was 1:1, we could assert that the count in the old cluster equalled the count in the new cluster.
Avoiding nested documents
The real trick in this was to focus on what supported queries we were running: search by tag value, and search by tag key and value.
The first query does not require nested documents since it works on a single field. For the latter, we did the following trick. We created a field that contains the combination of the key and the value. Whenever a user queries on a key, value match, we translate their request to the corresponding text and query against that field.
Example:
curl -X PUT "localhost:9200/my_index_2?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"tags": {
"type": "object",
"properties": {
"keyToValue": {
"type": "keyword"
},
"value": {
"type": "keyword"
}
}
}
}
}
}
}
'
curl -X PUT "localhost:9200/my_index_2/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"tags" : [
{
"keyToValue" : "John:Smith",
"value" : "Smith"
},
{
"keyToValue" : "Alice:White",
"value" : "White"
}
]
}
'
# Query by key,value
# User queries for key: Alice, and value : White , we then query elastic with this query:
curl -X GET "localhost:9200/my_index_2/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [ { "match": { "tags.keyToValue": "Alice:White" }}]
}}}
'
# Query by value only
curl -X GET "localhost:9200/my_index_2/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [ { "match": { "tags.value": "White" }}]
}}}
'
Chapter 6 — The migration process
We planned to migrate about 500 million documents with zero downtime. To do that we needed:
- A strategy on how to transfer data from the old Elastic to the new Elasticsearch
- A strategy on how to close the lag between the start of the migration and the end of it
And our two options in closing the lag:
- Our messaging system is Kafka based. We could have just taken the current offset before the migration started, and after the migration ended, start consuming from that specific offset. This solution requires some manual tweaking of offsets and some other stuff, but will work.
- Another approach to solving this issue was to start consuming messages from the beginning of the topic in Kafka and make our actions on Elasticsearch idempotent — meaning, if the change was “applied” already, nothing would change in Elastic store.
The requests made by our service against Elastic were already idempotent, so we choose option 2 because it required zero manual work (no need to take specific offsets, and then set them afterward in a new consumer group).
How can we migrate the data?
These were the options we thought of:
- If our Kafka contained all messages from the beginning of time, we could just play from the start and the end state would be equal. But since we apply retention to out topics, this was not an option.
- Dump messages to disk and then ingest them to Elastic directly – This solution looked kind of weird. Why store them in disk instead of just writing them directly to Elastic?
- Transfer messages between old Elastic to new Elastic — This meant, writing some sort of “script” (did anyone say Python? ?) that will connect to the old Elasticsearch cluster, query for items, transform them to the new schema, and index them in the cluster.
We choose the last option. These were the design choices we had in mind:
- Let’s not try to think about error handling unless we need to. Let’s try to write something super simple, and if errors occur, let’s try to address them. In the end, we did not need to address this issue since no errors occurred during the migration.
- It’s a one-off operation, so whatever works first / KISS.
- Metrics — Since the migration processes can take hours to days, we wanted the ability from day 1 to be able to monitor the error count and to track the current progress and copy rate of the script.

We thought long and hard and choose Python as our weapon of choice. The final version of the code is below:
dictor==0.1.2 - to copy and transform our Elasticsearch documentselasticsearch==1.9.0 - to connect to "old" Elasticsearchelasticsearch6==6.4.2 - to connect to the "new" Elasticsearchstatsd==3.3.0 - to report metrics
from elasticsearch import Elasticsearch
from elasticsearch6 import Elasticsearch as Elasticsearch6
import sys
from elasticsearch.helpers import scan
from elasticsearch6.helpers import parallel_bulk
import statsd
ES_SOURCE = Elasticsearch(sys.argv[1])
ES_TARGET = Elasticsearch6(sys.argv[2])
INDEX_SOURCE = sys.argv[3]
INDEX_TARGET = sys.argv[4]
QUERY_MATCH_ALL = {"query": {"match_all": {}}}
SCAN_SIZE = 1000
SCAN_REQUEST_TIMEOUT = '3m'
REQUEST_TIMEOUT = 180
MAX_CHUNK_BYTES = 15 * 1024 * 1024
RAISE_ON_ERROR = False
def transform_item(item, index_target):
# implement your logic transformation here
transformed_source_doc = item.get("_source")
return {"_index": index_target,
"_type": "_doc",
"_id": item['_id'],
"_source": transformed_source_doc}
def transformedStream(es_source, match_query, index_source, index_target, transform_logic_func):
for item in scan(es_source, query=match_query, index=index_source, size=SCAN_SIZE,
timeout=SCAN_REQUEST_TIMEOUT):
yield transform_logic_func(item, index_target)
def index_source_to_target(es_source, es_target, match_query, index_source, index_target, bulk_size, statsd_client,
logger, transform_logic_func):
ok_count = 0
fail_count = 0
count_response = es_source.count(index=index_source, body=match_query)
count_result = count_response['count']
statsd_client.gauge(stat='elastic_migration_document_total_count,index={0},type=success'.format(index_target),
value=count_result)
with statsd_client.timer('elastic_migration_time_ms,index={0}'.format(index_target)):
actions_stream = transformedStream(es_source, match_query, index_source, index_target, transform_logic_func)
for (ok, item) in parallel_bulk(es_target,
chunk_size=bulk_size,
max_chunk_bytes=MAX_CHUNK_BYTES,
actions=actions_stream,
request_timeout=REQUEST_TIMEOUT,
raise_on_error=RAISE_ON_ERROR):
if not ok:
logger.error("got error on index {} which is : {}".format(index_target, item))
fail_count += 1
statsd_client.incr('elastic_migration_document_count,index={0},type=failure'.format(index_target),
1)
else:
ok_count += 1
statsd_client.incr('elastic_migration_document_count,index={0},type=success'.format(index_target),
1)
return ok_count, fail_count
statsd_client = statsd.StatsClient(host='localhost', port=8125)
if __name__ == "__main__":
index_source_to_target(ES_SOURCE, ES_TARGET, QUERY_MATCH_ALL, INDEX_SOURCE, INDEX_TARGET, BULK_SIZE,
statsd_client, transform_item)
Conclusion
Migrating data in a live production system is a complicated task that requires a lot of attention and careful planning. I recommend taking the time to work through the steps listed above and figure out what works best for your needs.
As a rule of thumb, always try to reduce your requirements as much as possible. For example, is a zero downtime migration required? Can you afford data-loss?

Upgrading data stores is usually a marathon and not a sprint, so take a deep breath and try to enjoy the ride.
- The whole process listed above took me around 4 months of work
- All of the Elasticsearch examples that appear in this post have been tested against version 6.8.1