
by Pritish Vaidya
Accurate estimation of read time for Medium articles in JavaScript

Introduction
Read Time Estimate is the estimation of the time taken by the reader to read an article. It has been a part of Medium’s core features since it launched in 2013.
As explained in the New Yorker:
The more we know about something — including precisely how much time it will consume — the greater the chance we will commit to it.
Knowing in advance how long an article will take to read helps with better time management by allowing us to plan further ahead.
Why should I use a new script?
Yes, there are many open source libraries available on npm but they contain several flaws.
Before that, let’s take a look at these two articles on Medium.
The above two articles have the following key features
- Average Read Time (English) — 265 Words per min
- Average Read Time (Chinese, Japanese and Korean) — 500 Characters/min
- Image Read Time — 12 seconds for the first image, 11 for the second, and minus an additional second for each subsequent image. Other images counted at 3 seconds.
Most of the libraries don’t account for the above features completely. They use HTML strings as is without omitting its tag names which increases the deviation of estimation from the original value.
Code
The code can be split into three parts:
- Constants
- Utility
- Main
Constants
The constants can be used as defaults to the main function. The image tag has its own use which will be defined later.

Utility Functions
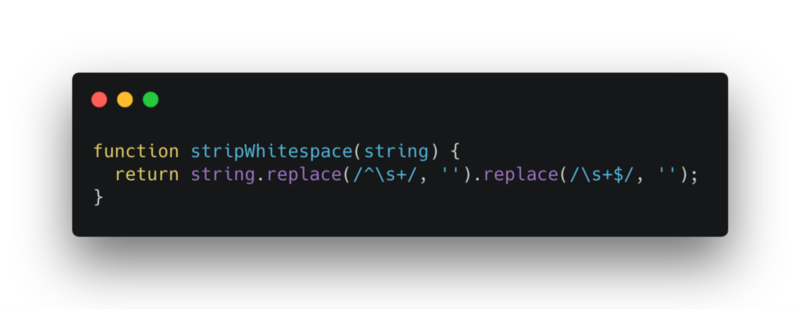
- Strip WhiteSpace
It is a simple utility function to remove all leading and trailing whitespace from the string provided.
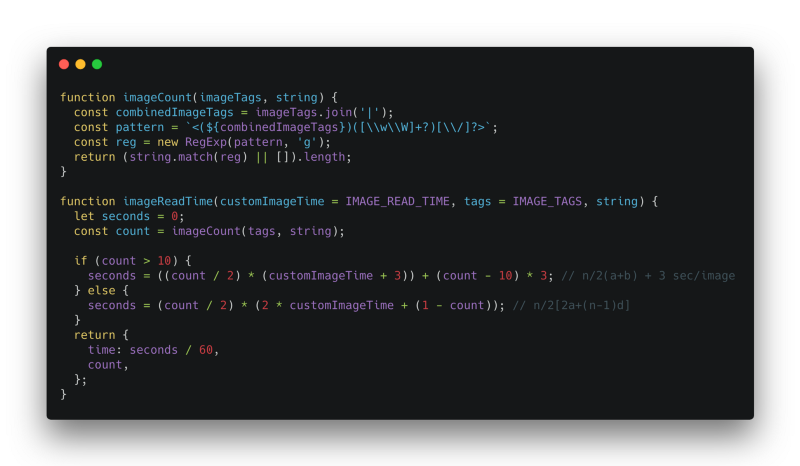
2. Image Read Time
It parses the string, looks for any HTML image tags based on the defaults provided in the constants and returns the count.
If the image count is greater than 10, we calculate the image read time of the first 10 images in decreasing arithmetic progression starting from 12 sec / customReadTime provided by the user using the simple formula n * (a+b) / 2 and 3 sec for the remaining images.
3. Strip Tags
Next, we check for any HTML tags (both) in the string and remove it to extract only the words from it.

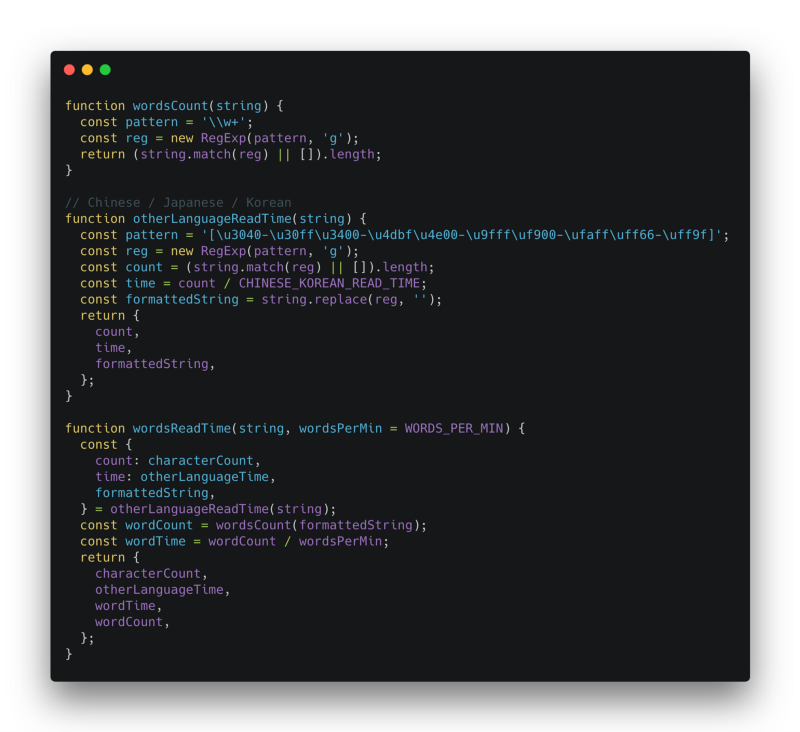
4. Words Read Time
This utility function calculates the words count and Chinese / Korean and Japanese characters using the different Unicode character range.
The time is calculated by dividing it with the constants defined above.
5. Humanize Time
Based on the distance of time in words, we can calculate and return the humanized duration of the time taken to read.

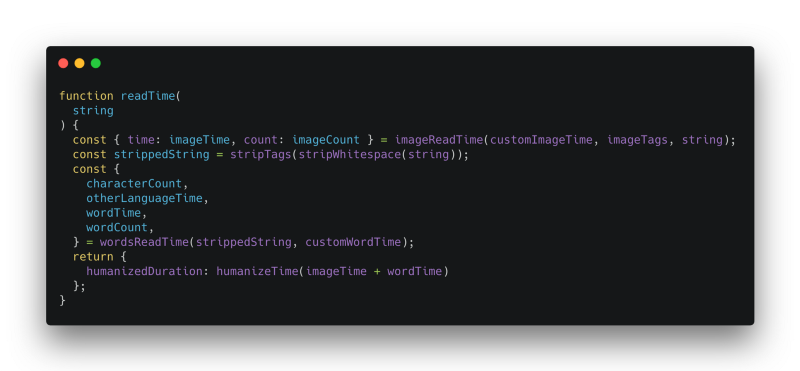
Main
The main function only consolidates all the utility methods in the correct order.
How accurate is this script?
Taking the tests on the HTML string (from the Chrome inspector) before this article section.
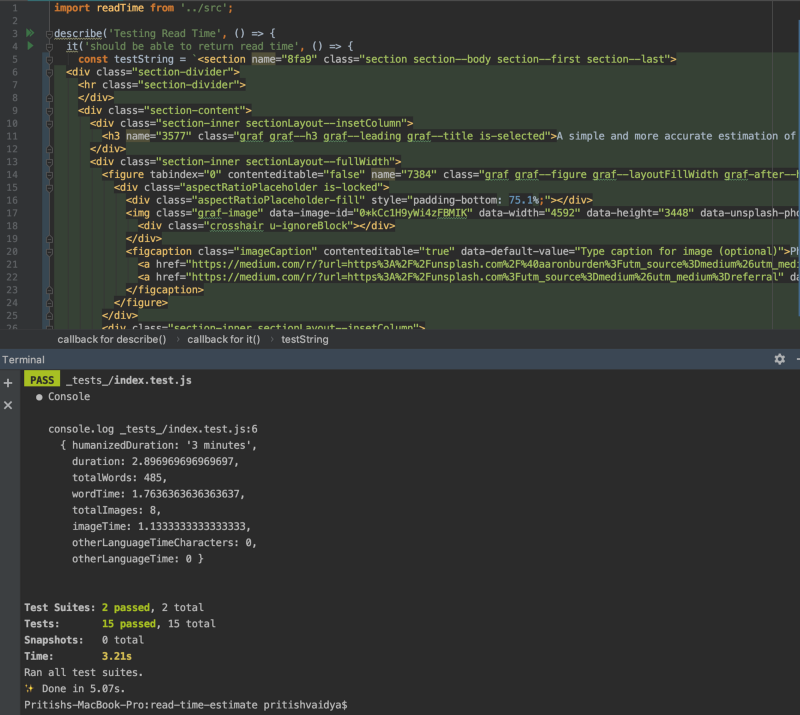

The tests and the Pages clearly give the correct estimate about the total words from the parsed HTML and the number of images.
Links
I’ve consolidated the complete code on GitHub. It is also available as an npm package read-time-estimate.
More of the cool stuff can be found on my StackOverflow and GitHub profiles.
Follow me on LinkedIn, Medium, Twitter for further update new articles.
One clap, two claps, three claps, forty?

Originally published at blog.pritishvaidya.com on January 30, 2019.