

S3 is an Amazon Web Service that provides data storage and retrieval in the cloud.
This article will discuss the common S3 performance bottlenecks and how they impact the service's overall performance. It will also share some best practices to serve as guidelines for optimising the performance of your S3.
By the end, you'll have practical tips to ensure your AWS S3 runs at its best and handles all your data smoothly.
S3 Performance Bottlenecks
Here are some common bottlenecks that influence the overall performance of S3:
Network Latency:
Network latency is the delay incurred when data travels between your application and the S3 storage. This delay arises due to the physical distance, the number of network hops, and the speed at which data can be transmitted.
In simpler terms, it's like the time it takes for your request to reach the S3 server and the response to find its way back.
Request Processing Time:
When you send a request to Amazon S3, the time it takes for the system to comprehend and fulfill that request is called request processing time. It involves authentication, authorisation, and any necessary computation before responding.
Server-Side Processing:
Once your request reaches the S3 server, it undergoes processing to fulfill your requested action. This can involve tasks like encryption, access control checks, and other operations that impact the time it takes to serve your data.
While these operations are essential, they can become bottlenecks if not managed efficiently.
Impact of Bottlenecks on Overall S3 Performance
These bottlenecks, individually or collectively, can affect the overall performance of Amazon S3. Here are some of the impacts:
Slower Data Retrieval:
Network latency and request processing time can lead to delays in retrieving data, affecting the overall speed of your applications relying on S3. Slow data retrieval can impact user experience and application responsiveness, such as waiting for a webpage to load.
Reduced Throughput:
Bottlenecks, especially in server-side processing and request processing time, can limit the amount of data transferred at a given time. This reduction in throughput can impact the speed at which your applications can read or write data to S3.
Increased Costs:
Inefficiencies in data transfer and processing can contribute to increased costs. Longer processing times and additional network usage can result in higher expenses for S3 usage. Identifying and mitigating bottlenecks can lead to cost savings and more efficient resource utilisation.
Understanding and addressing these common bottlenecks is essential for unlocking the full potential of Amazon S3. The following section will address the best practices to optimise S3 performance and ensure a seamless cloud storage experience.
Best Practices for S3 Performance Optimization
Amazon S3 Transfer Acceleration
Transferring data to and from Amazon S3 may take time due to the physical distance between your location and the S3 server.
Amazon S3 Transfer Acceleration is a bucket-level feature that enables fast, easy, and secure transfers of files over long distances between your client and an S3 bucket.
When to opt for transfer acceleration
You might want to use Transfer Acceleration on a bucket for various reasons:
- If you're far from the S3 server, Transfer Acceleration is your shortcut. It's like taking a direct flight instead of a connecting one.
- For real-time applications or situations where time is of the essence, the speed boost from Transfer Acceleration can be a game-changer.
- You need to transfer gigabytes to terabytes of data regularly across continents.
- You can't use all of your available bandwidth over the internet when uploading to Amazon S3.
Things to keep in mind
- Cost Considerations: While Transfer Acceleration speeds up your data, it comes with additional costs.
- The bucket name used for Transfer Acceleration must be DNS-compliant and not contain periods (".").
- Transfer Acceleration must be enabled on the bucket.
- After you enable Transfer Acceleration on a bucket, it might take up to 20 minutes before the data transfer speed to the bucket increases.
- Transfer Acceleration is only supported in certain following regions.
- You must be the bucket owner to set the transfer acceleration state.
Benefits of Transfer Acceleration
- Faster Uploads and Downloads: Your data gets to its destination quicker, making uploads and downloads snappier. It's like sending a package with express shipping instead of regular mail.
- Improved User Experience: For applications relying on S3, users experience reduced wait times.
- Global Reach, Local Touch: Whether your users are in New York, Tokyo, or spread around the world, they experience speed as if the data is right next door. It's like having a local store in every city.
AWS provides a Transfer Acceleration speed comparison tool so that a comparison can be made between accelerated and non-accelerated S3 transfer.
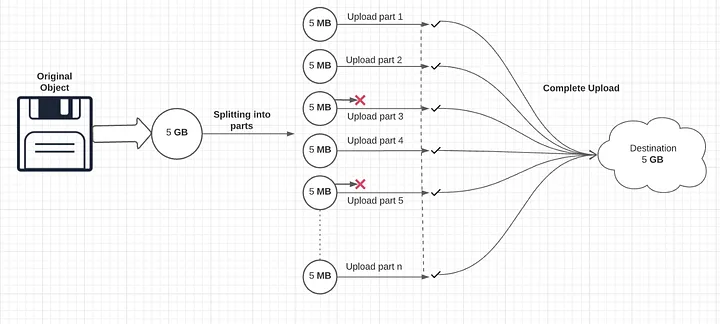
Multi-part Uploads
By default, when you upload an object to S3, it is uploaded as a single blob of data in a single stream. S3 uses the PUT operation for uploads, which limits the speed and reliability of the upload because of the single stream of data constraint.
Instead of attempting to upload one colossal file, multi-part uploads divide it into smaller, manageable pieces. The minimum data size for an upload is 100MB, and you shouldn't use a multi-part upload if your data is smaller than this.
An upload can be split into a maximum of 10,000 parts, and each part can range between 5MB and 5GB. Each of the individual parts is isolated from the rest, which means the failure of one part doesn't affect the other parts.
When to opt for multi-part uploads
- Large File Sizes: Multi-part uploads should become your go-to strategy for dealing with several gigabytes or more files.
- Unstable Internet Connections: In areas where the internet connection may not be consistent, multi-part uploads act as a safety net. It's like having a backup plan for your data transfer.
Benefits of multi-part uploads
- Faster Uploads: Multi-part uploads speed up the process. It's like assembling a team to work on different project sections simultaneously, ensuring a quicker completion.
- Reliability in Unstable Connections: In scenarios where your internet connection might have a hiccup, multi-part uploads ensure the upload doesn't fail. It's similar to saving your progress in a game – even if the power goes out, you don't lose everything.
- Optimised for Large Files: When dealing with extensive files, multi-part uploads are like breaking them into manageable chapters. It accelerates the process and simplifies troubleshooting if an issue arises.
To implement multi-part uploads, you can find the detailed steps via AWS Documentation
Measuring Performance and Monitoring
To ensure your Amazon S3 storage operates at its best, keeping an eye on its performance is like giving it a regular check-up. Here's a straightforward guide on how to measure performance and monitor your S3 environment efficiently:
- Network Throughput, CPU, and DRAM: Imagine S3 as a bustling marketplace. To optimise, check the "foot traffic" (network throughput), the "workers' efficiency" (CPU), and the "storage capacity" (DRAM). If any of these are congested, it might be time to consider different "worker" types – or, in AWS terms, Amazon EC2 instance types.
- Use HTTP analysis tools to ensure your data is moving swiftly and efficiently.
- Monitor the number of error 503 (Slow Down) Status Error Responses by using Amazon Cloudwatch, Amazon S3 Storage Lens, and Amazon S3 Server Access Logging.
- Use CloudWatch for Insights on your S3 Performance: CloudWatch uses metrics and dimensions to visualise S3's operational health. Metrics are the data points, such as the number of requests made to an S3 bucket, and dimensions represent a key-value pair of the identity of the metric, helping you filter and focus on specific aspects, like testing environments. CloudWatch presents your data visually, like a set of easy-to-read charts. It's like a health report for your S3. Alarms act as your alert system, notifying you if something needs immediate attention.
Use Byte-Range Fetches
Optimising the retrieval of objects from Amazon S3 involves a technique known as Byte-Range Fetches. Utilising the Range HTTP header within a GET Object request, you can selectively fetch specific byte ranges from an object, transmitting only the designated portion.
This approach is efficient when dealing with large objects. Fetching smaller ranges boosts aggregate throughput and facilitates more efficient retry times in case of interrupted requests.
For seamless integration with multi-part uploads, it is recommended to align the byte-range sizes with the sizes of the parts used during the upload process. This alignment ensures optimal performance, and GET requests can directly target individual parts, such as using the syntax GET ?partNumber=N.
CloudFront
CloudFront is a global content delivery network (CDN) that provides viewers with swift content delivery marked by low latency and high transfer speeds.
Leveraging a network of strategically positioned edge locations, CloudFront intelligently caches copies of your S3 content, ensuring proximity to the viewer. This proximity reduces the distance travelled by cached content requests and responses compared to direct routes to your S3 region, resulting in significantly improved performance.
For content not cached, CloudFront seamlessly retrieves it from S3, caching it as necessary.
CloudFront offers security enhancements by restricting direct access to S3 and allowing content access exclusively through CloudFront. This restriction is implemented using an origin access identity (OAI).
Additionally, HTTPS encryption can be enforced for situations requiring encryption-in-transit between CloudFront and the viewer, adding an extra layer of security to the content delivery process.
To achieve high performance, CloudFront incorporates various optimisations, including TLS session resumption, TCP fast open, OCSP stapling, S2N, and request collapsing. It supports a range of HTTP protocols, including HTTP/1.0, HTTP/1.1, HTTP/2, and HTTP/3.
S3 Select
S3 Select offers a streamlined approach to fetching specific data from object contents using SQL expressions. It enhances precision in data retrieval, contributes to cost savings, and improves overall performance by minimising the amount of data transferred.
S3 Select is versatile, operating seamlessly on objects stored in CSV, JSON, and Apache Parquet formats. This flexibility accommodates various data structures and types. It extends its capabilities to objects compressed with GZip and BZip2, ensuring that even compressed CSV and JSON files can be efficiently processed.
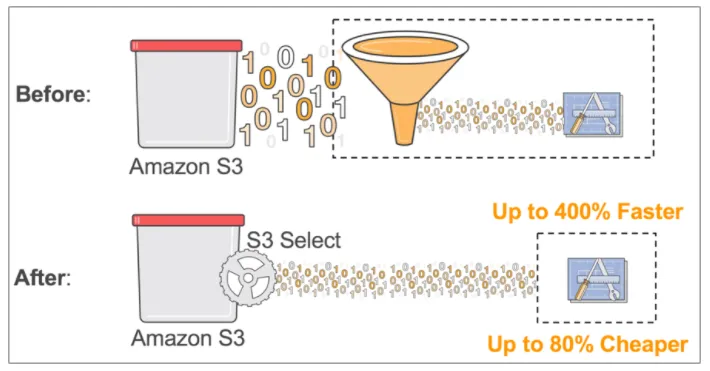 A diagram that illustrates S3 select method (from here).
A diagram that illustrates S3 select method (from here).
By employing S3 Select, unnecessary data transfer is curtailed. This reduction in transferred data directly translates to cost savings, as only the required information is transmitted.
The streamlined data retrieval process enhances overall performance by ensuring that the SQL expressions used in S3 Select efficiently fetch the necessary data, contributing to a more responsive and agile system.
Conclusion
Optimising Amazon S3 performance is essential for faster storage and retrieval of data in the cloud.
Identifying and addressing common bottlenecks, such as network latency and server-side processing delays, forms the foundation of a high-performing S3 environment.
Then, implementing best practices like multi-part uploads, Amazon S3 Transfer Acceleration, and CloudFront integration streamlines operations and enhances efficiency.
The power of S3 Select provides precision and agility in data retrieval and monitoring tools like CloudWatch to respond to 503 error signals and keep S3 health in check.
As the cloud environment changes, adopting these practices ensures not just optimal S3 performance but a resilient and future-ready cloud storage infrastructure.