
By Zach Caceres
GNU parallel is a command line tool for running jobs in parallel.
parallel is awesome and belongs in the toolbox of every programmer. But I found the docs a bit overwhelming at first. Fortunately, you can start being useful with parallel with just a few basic commands.
Why is parallel so useful?
Let’s compare sequential and parallel execution of the same compute-intensive task.
Imagine you have a folder of .wav audio files to convert to .flac:
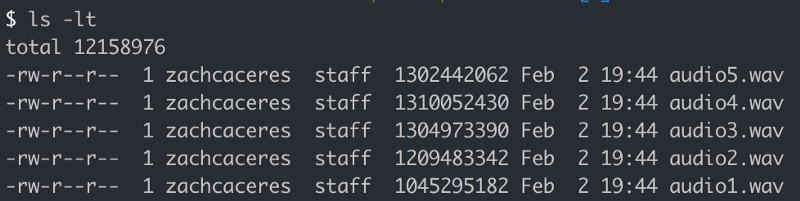
These are pretty big files, each one is at least a gigabyte.
We’ll use another great command line tool, ffmpeg, to convert the files. Here’s what we need to run for each file.
ffmpeg -i audio1.wav audio1.flac
Let’s write a script to convert each one sequentially:
# convert.sh
ffmpeg -i audio1.wav audio1.flac
ffmpeg -i audio2.wav audio2.flac
ffmpeg -i audio3.wav audio3.flac
ffmpeg -i audio4.wav audio4.flac
ffmpeg -i audio5.wav audio5.flac
We can time the execution of a job by prepending time when calling the script from the terminal. time will print the real time elapsed during execution.
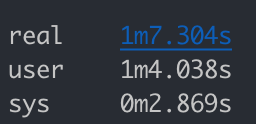
time ./convert.sh
Our script finishes in a little over a minute.
Not bad. But now let’s run it in parallel!
We don’t have to change anything about our script. With the -a flag, we can pipe our script directly into parallel. parallel will run every line as a separate command.
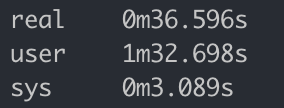
parallel -a ./convert.sh
Using parallel, our conversion ran in a little over half the time. Nice!
With only five files, this difference isn’t such a big deal. But with larger lists and longer tasks, we can save a lot of time with parallel.
I encountered parallel while working with a data processing task that would likely have run for an hour or more if done sequentially. With parallel, it took only a few minutes.
parallel power also depends on your computer. My MacBook Pro’s Intel i7 has only 4 cores. Even this small task pushed them all to their limit:
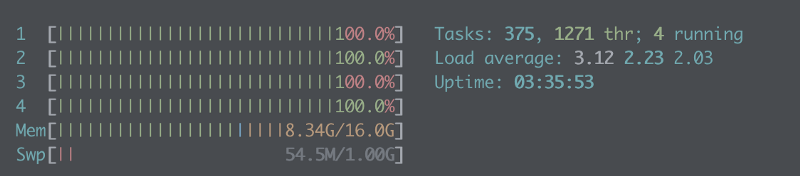
More powerful computers might have processors with 8, 16, or even 32 cores, offering massive time-saving through parallelization of your jobs.
Being Useful with parallel
The other great benefit of parallel is its brevity and simplicity. Let's start with a nasty Python script and convert it to a clean call to parallel.
Here’s a Python script to accomplish our audio file conversion:
import subprocess
path = Path.home()/'my-data-here'
for audio_file in list(path.glob('*.wav')):
cmd = ['ffmpeg',
'-i',
str(audio_file),
f'{audio_file.name.split(".")[0]}.flac']
subprocess.run(cmd, stdout=subprocess.PIPE)
Yikes! That’s actually a lot of code to think about just to convert some files. (This takes about 1.2 minutes to run).
Let’s convert our Python to parallel.
Calling a script with parallel -a
parallel -a your-script-here.sh is the nice one-liner we used above to pipe in our bash script.
This is great but does require you to write out the bash script you want to execute. In our example, we still wrote out every individual call to ffmpeg in convert.sh.
Pipes and String Interpolation with parallel
Luckily, parallel gives us a way to delete convert.sh entirely.
Here’s all we have to run to accomplish our conversion:
ls *.wav | parallel ffmpeg -i {} {.}.flac
Let’s break this down.
We’re getting a list of all the .wav files in our directory with ls *.wav. Then we’re piping (|) that list to parallel.
Parallel provides some useful ways to do string interpolation, so our file paths are input correctly.
The first is {}, which parallel automatically replaces with one line from our input.
The second operator is {.}, which will input one line but with any file extensions removed.
If we expanded the command run by parallel for our first line of input, we would see...
ffmpeg -i audio1.wav audio1.flac
Args with Parallel
As it turns out, we don’t even need to pipe from ls to complete our task. We can go simpler still:
parallel ffmpeg -i {} {.}.flac ::: *.wav
Arguments passed to parallel occur after the command and are separated by :::. In this case, our argument is *.wav, which will provide the list of all .wav files in our directory. These files become the input for our blazing-fast parallel job.
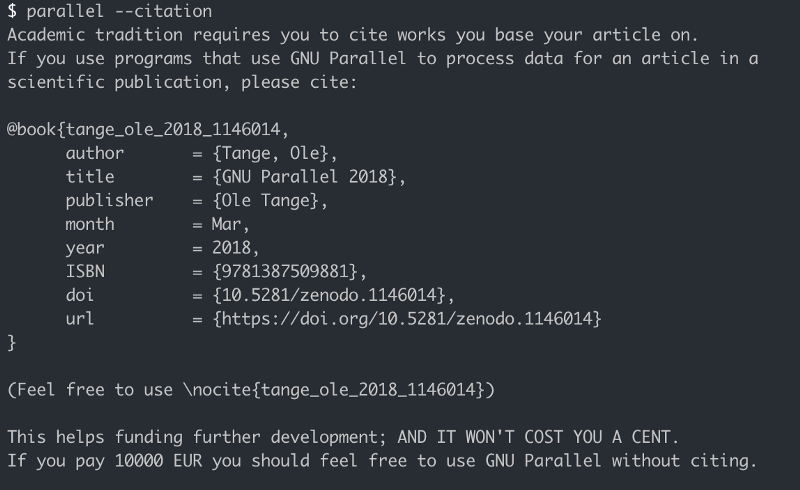
Fun fact: parallel was built by Ole Tange and published in 2011. According to him, you can use the tool for research without citing the source paper for the modest fee of 10,000 euros!
Thanks for reading!