
By Vlad Wetzel
Finding your next programming book is hard, and it’s risky.
As a developer, your time is scarce, and reading a book takes up a lot of that time. You could be programming. You could be resting. But instead you’re allocating precious time to read and expand your skills.
So which book should you read? My colleagues and I often discuss books, and I’ve noticed that our opinions on a given book vary wildly.
So I decided to take a deeper look into the problem. My idea: to parse the most popular programmer resource in the world for links to a well-known book store, then count how many mentions each book has.
Fortunately, Stack Exchange (the parent company of Stack Overflow) had just published their data dump. So I sat down and got to coding.
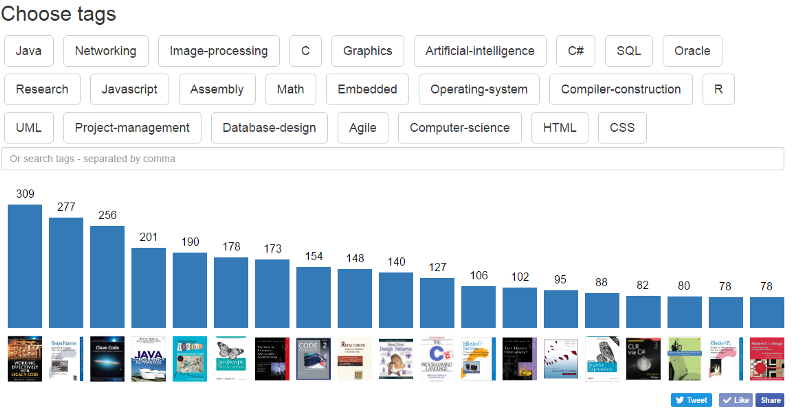 _A screenshot from the tool I built: [dev-books.com](http://www.dev-books.com" rel="noopener" target="blank" title=")
_A screenshot from the tool I built: [dev-books.com](http://www.dev-books.com" rel="noopener" target="blank" title=")
“If you’re curious, the overall top recommended book is Working Effectively with Legacy Code, with Design Pattern: Elements of Reusable Object-Oriented Software coming in second. While the titles for these are as dry as the Atacama Desert, the content should still be quality. You can sort books by tags, like JavaScript, C, Graphics, and whatever else. This obviously isn’t the end-all of book recommendations, but it’s certainly a good place to start if you’re just getting into coding or looking to beef up your knowledge.” — review on Lifehacker.com
Shortly afterward, I launched dev-books.com, which allows you to explore all the data I gathered and sorted. I got more than 100,000 visitors and received lots of feedback asking me to describe the whole technical process.
So, as promised, I’m going to describe how I built everything right now.
Getting and importing the data
I grabbed the Stack Exchange database dump from archive.org.
From the very beginning I realized it would not be possible to import a 48GB XML file into a freshly created database (PostgreSQL) using popular methods like myxml := pg_read_file(‘path/to/my_file.xml’), because I didn’t have 48GB of RAM on my server. So, I decided to use a SAX parser.
All the values were stored between <row> tags, so I used a Python script to parse it:
After three days of importing (almost half of the XML was imported during this time), I realized that I’d made a mistake: the ParentID attribute should have been ParentId.
At this point, I didn’t want to wait for another week, and moved from an AMD E-350 (2 x 1.35GHz) to an Intel G2020 (2 x 2.90GHz). But this still didn’t speed up the process.
Next decision — batch insert:
StringIO lets you use a variable like file to handle the function copy_from, which uses COPY. This way, the whole import process only took one night.
OK, time to create indexes. In theory, GiST indexes are slower than GIN, but take less space. So I decided to use GiST. After one more day, I had an index that took 70GB.
When I tried couple of test queries, I realized that it takes way too much time to process them. The reason? Disk IO waits. SSD GOODRAM C40 120Gb helped a lot, even if it is not the fastest SSD so far.
I created a brand new PostgreSQL cluster:
initdb -D /media/ssd/postgresq/data
Then I made sure to change the path in my service config (I used Manjaro OS):
vim /usr/lib/systemd/system/postgresql.service
Environment=PGROOT=/media/ssd/postgresPIDFile=/media/ssd/postgres/data/postmaster.pid
I Reloaded my config and started postgreSQL:
systemctl daemon-reloadpostgresql systemctl start postgresql
This time it took couple hours to import, but I used GIN. The indexing took 20GB of space on SSD, and simple queries were taking less than a minute.
Extracting books from the database
With my data finally imported, I started to look for posts that mentioned books, then copied them over to a separate table using SQL:
CREATE TABLE books_posts AS SELECT * FROM posts WHERE body LIKE ‘%book%’”;
The next step was to find all the hyperlinks within those:
CREATE TABLE http_books AS SELECT * posts WHERE body LIKE ‘%http%’”;
At this point I realized that StackOverflow proxies all links like: rads.stackowerflow.com/[$isbn]/
I created another table with all posts with links:
CREATE TABLE rads_posts AS SELECT * FROM posts WHERE body LIKE ‘%http://rads.stackowerflow.com%'";
Using regular expressions to extract all the ISBNs. I extracted Stack Overflow tags to another table through regexp_split_to_table.
Once I had the most popular tags extracted and counted, the top of 20 most mentioned books by tags were quite similar across all tags.
My next step: refining tags.
The idea was to take the top-20-mentioned books from each tag and exclude books which were already processed.
Since it was “one-time” job, I decided to use PostgreSQL arrays. I wrote a script to create a query like so:
With the data in hand, I headed for the web.
Building the web app
Since I’m not a web developer — and certainly not a web user interface expert — I decided to create a very simple single-page app based on a default Bootstrap theme.
I created a “search by tag” option, then extracted the most popular tags to make each search clickable.
I visualized the search results with a bar chart. I tried out Hightcharts and D3, but they were more for dashboards. These had some issues with responsiveness, and were quite complex to configure. So, I created my own responsive chart based on SVG. To make it responsive, it has to be redrawn on screen orientation change event:
Web server failure
 Nginx vs. Apache
Nginx vs. Apache
Right after I published dev-books.com I had a huge crowd checking out my web site. Apache couldn’t serve for more than 500 visitors at the same time, so I quickly set up Nginx and switched to it on the way. I was really surprised when real-time visitors shot up to 800 at same time.
Conclusion:
I hope I explained everything clearly enough for you to understand how I built this. If you have any questions, feel free to ask. You can find me on twitter and Facebook.
As promised, I will publish my full report from Amazon.com and Google Analytics at the end of March. The results so far have been really surprising.
Make sure you click on green heart below and follow me for more stories about technology :)
Stay tuned at dev-books.com