
By Timber.io
What Is Threading? Why Might You Want It?
Python is a linear language. However, the threading module comes in handy when you want a little more processing power.
Threading in Python cannot be used for parallel CPU computation. But it is perfect for I/O operations such as web scraping, because the processor is sitting idle waiting for data.
Threading is game-changing, because many scripts related to network/data I/O spend the majority of their time waiting for data from a remote source.
Because downloads might not be linked (for example, if you are scraping separate websites), the processor can download from different data sources in parallel and combine the result at the end.
For CPU intensive processes, there is little benefit to using the threading module.
Threading is included in the standard library:
import threading from queueimport Queueimport time
You can use target as the callable object, args to pass parameters to the function, and start to start the thread.
def testThread(num): print numif __name__ == '__main__': for i in range(5): t = threading.Thread(target=testThread, arg=(i,)) t.start()
If you’ve never seen if __name__ == '__main__': before, it's basically a way to make sure the code that's nested inside it will only run if the script is run directly (not imported).
The Lock
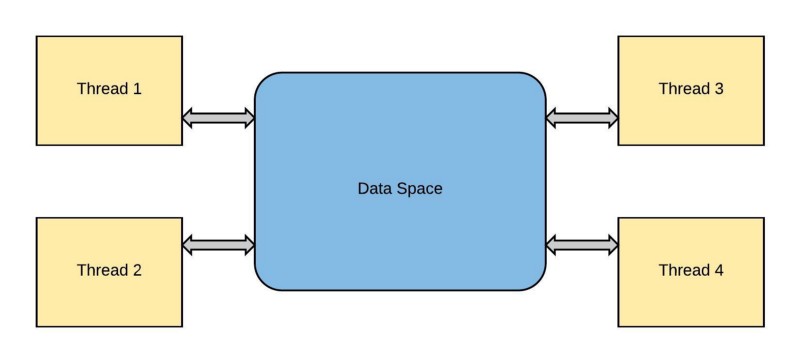
You’ll often want your threads to be able to use or modify variables common between threads. To do this, you’ll have to use something known as a lock.
Whenever a function wants to modify a variable, it locks that variable. When another function wants to use a variable, it must wait until that variable is unlocked.
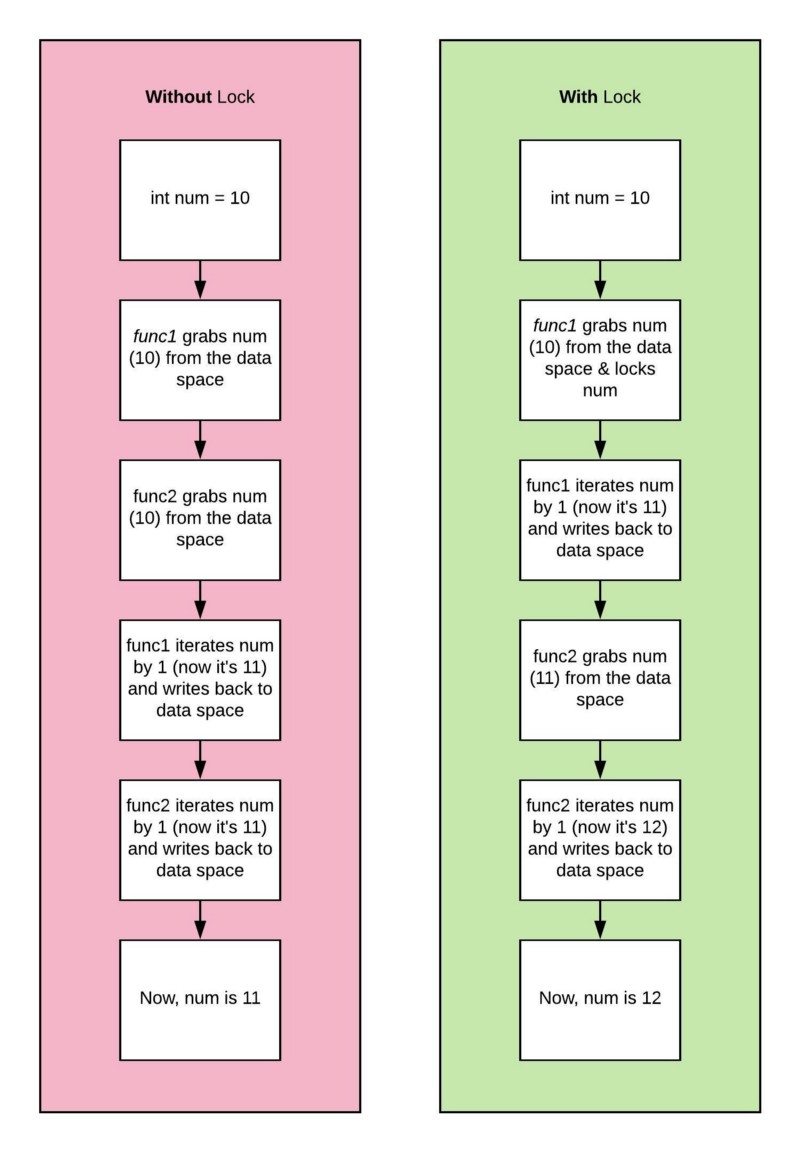
Imagine two functions which both iterate a variable by 1. The lock allows you to ensure that one function can access the variable, perform calculations, and write back to that variable before another function can access the same variable.
You can use a print lock to ensure that only one thread can print at a time. This prevents the text from getting jumbled up (and causing data corruption) when you print.
In the code below, we’ve got ten jobs that we want to get done and five workers that will work on the job:
print_lock = threading.Lock()def threadTest(): # when this exits, the print_lock is released with print_lock: print(worker)def threader(): while True: # get the job from the front of the queue threadTest(q.get()) q.task_done()q = Queue()for x in range(5): thread = threading.Thread(target = threader) # this ensures the thread will die when the main thread dies # can set t.daemon to False if you want it to keep running t.daemon = True t.start()for job in range(10): q.put(job)
Multithreading is not always the perfect solution
I find that many guides tend to skip the negatives of using the tool they’ve just been trying to teach you. It’s important to understand that there are both pros and cons associated with using all these tools. For example:
- There is overhead associated with managing threads, so you don’t want to use it for basic tasks (like the example)
- Threading increases the complexity of the program, which can make debugging more difficult
What is Multiprocessing? How is it different from threading?
Without multiprocessing, Python programs have trouble maxing out your system’s specs because of the GIL (Global Interpreter Lock). Python wasn't designed considering that personal computers might have more than one core (which shows you how old the language is).
The GIL is necessary because Python is not thread-safe, and there is a globally enforced lock when accessing a Python object. Though not perfect, it's a pretty effective mechanism for memory management. What can we do?
Multiprocessing allows you to create programs that can run concurrently (bypassing the GIL) and use the entirety of your CPU core. Though it is fundamentally different from the threading library, the syntax is quite similar. The multiprocessing library gives each process its own Python interpreter, and each their own GIL.
Because of this, the usual problems associated with threading (such as data corruption and deadlocks) are no longer an issue. Since the processes don’t share memory, they can’t modify the same memory concurrently.
Let’s get started
import multiprocessingdef spawn(): print('test!')if __name__ == '__main__': for i in range(5): p = multiprocessing.Process(target=spawn) p.start()
If you have a shared database, you want to make sure that you’re waiting for relevant processes to finish before starting new ones.
for i in range(5): p = multiprocessing.Process(target=spawn) p.start() p.join() # this line allows you to wait for processes
If you want to pass arguments to your process, you can do that with args:
import multiprocessingdef spawn(num): print(num)if __name__ == '__main__': for i in range(25): ## right here p = multiprocessing.Process(target=spawn, args=(i,)) p.start()
Here’s a neat example, because the numbers don’t come in the order you’d expect (without the p.join()).
Drawbacks
As with threading, there are still drawbacks with multiprocessing … you’ve got to pick your poison:
- There is I/O overhead from data being shuffled around between processes
- The entire memory is copied into each subprocess, which can be a lot of overhead for more significant programs
Conclusion
When should you use multithreading vs multiprocessing?
- If your code has a lot of I/O or Network usage, multithreading is your best bet because of its low overhead.
- If you have a GUI, use multithreading so your UI thread doesn’t get locked up.
- If your code is CPU bound, you should use multiprocessing (if your machine has multiple cores)
Just a disclaimer: we’re a logging company here @ Timber. We’d love it if you tried out our product (it’s seriously great!), but that’s all we’re going to advertise it.
If you’re interested in getting more posts from Timber in your inbox, feel free to sign up here. We promise there’ll be no spam, just great content on a weekly basis.
Originally published at timber.io.