
By Peter Gleeson
PostgreSQL is one of the most popular open source SQL dialects. One of its main advantages is the ability to extend its functionality with some inbuilt tools.
Here, let's look at a few PostgreSQL tricks that you can start using to take your SQL skills to the next level.
You'll find out how to:
- Quickly copy files into a database
- Summarise data in crosstab format
- Take advantage of arrays and JSON data in SQL
- Work with geometric data
- Run statistical analyses directly on your database
- Use recursion to solve problems
Copy data from a file
An easy way to quickly import data from an external file is to use the COPY function. Simply create the table you want to use, then pass in the filepath of your dataset to the COPY command.
The example below creates a table called revenue and fills it from a randomly generated CSV file.
You can include extra parameters, to indicate the filetype (here, the file is a CSV) and whether to read the first row as column headers.
You can learn more here.
CREATE TABLE revenue (
store VARCHAR,
year INT,
revenue INT,
PRIMARY KEY (product, year)
);
COPY revenue FROM '~/Projects/datasets/revenue.csv' WITH HEADER CSV;
Summarise data using the crosstab function
If you fancy yourself as a spreadsheet pro, you will probably be familiar with creating pivot tables from dumps of data. You can do the same in PostgreSQL with the crosstab function.
The crosstab function can take data in the form on the left, and summarise it in the form on the right (which is much easier to read). The example here will follow on with the revenue data from before.

First, enable the tablefunc extension with the command below:
CREATE EXTENSION tablefunc;
Next, write a query using the crosstab function:
SELECT * FROM CROSSTAB(
'SELECT
*
FROM revenue
ORDER BY 1,2'
)
AS summary(
store VARCHAR,
"2016" INT,
"2017" INT,
"2018" INT
);
There are two things to consider when using this function.
- First, pass in a query selecting data from your underlying table. You may simply select the table as it is (as shown here). However, you might want to filter, join or aggregate if required. Be sure to order the data correctly.
- Then, define the output (in the example, the output is called 'summary', but you can call it any name). List the column headers you want to use and the data type they will contain.
The output will be as shown below:
store | 2016 | 2017 | 2018
---------+---------+---------+---------
Alpha | 1637000 | 2190000 | 3287000
Bravo | 2205000 | 982000 | 3399000
Charlie | 1549000 | 1117000 | 1399000
Delta | 664000 | 2065000 | 2931000
Echo | 1795000 | 2706000 | 1047000
(5 rows)
Work with arrays and JSON
PostgreSQL supports multi-dimensional array data types. These are comparable to similar data types in many other languages, including Python and JavaScript.

You might want to use them in situations where it helps to work with more dynamic, less-structured data.
For example, imagine a table describing published articles and subject tags. An article could have no tags, or it could have many. Trying to store this data in a structured table format would be unnecessarily complicated.
You can define arrays using a data type, followed by square brackets. You can optionally specify their dimensions (however, this is not enforced).
For example, to create a 1-D array of any number of text elements, you would use text[]. To create a three-by-three two dimensional array of integer elements, you would use int[3][3].
Take a look at the example below:
CREATE TABLE articles (
title VARCHAR PRIMARY KEY,
tags TEXT[]
);
To insert arrays as records, use the syntax '{"first","second","third"}'.
INSERT INTO articles (title, tags)
VALUES
('Lorem ipsum', '{"random"}'),
('Placeholder here', '{"motivation","random"}'),
('Postgresql tricks', '{"data","self-reference"}');
There are a lot of things you can do with arrays in PostgreSQL.
For a start, you can check if an array contains a given element. This is useful for filtering. You can use the "contains" operator @> to do this. The query below finds all the articles which have the tag "random".
SELECT
*
FROM articles
WHERE tags @> '{"random"}';
You can also concatenate (join together) arrays using the || operator, or check for overlapping elements with the && operator.
You can search arrays by index (unlike many languages, PostgreSQL arrays start counting from one, instead of zero).
SELECT
tags[1]
FROM articles;
As well as arrays, PostgreSQL also lets you use JSON as a data type. Again, this provides the advantages of working with unstructured data. You can also access elements by their key name.
CREATE TABLE sessions (
session_id SERIAL PRIMARY KEY,
session_info JSON
);
INSERT INTO sessions (session_info)
VALUES
('{"app_version": 1.0, "device_type": "Android"}'),
('{"app_version": 1.2, "device_type": "iOS"}'),
('{"app_version": 1.4, "device_type": "iOS", "mode":"default"}');
Again, there are many things you can do with JSON data in PostgreSQL. You can use the -> and ->> operators to "unpackage" the JSON objects to use in queries.
For example, this query finds the values of the device_type key:
SELECT
session_info -> 'device_type' AS devices
FROM sessions;
And this query counts how many sessions were on app version 1.0 or earlier:
SELECT
COUNT(*)
FROM sessions
WHERE CAST(session_info ->> 'app_version' AS decimal) <= 1.0;
Run statistical analyses
Often, people see SQL as good for storing data and running simple queries, but not for running more in-depth analyses. For that, you should use another tool such as Python or R or your favourite spreadsheet software.
However, PostgreSQL brings with it enough statistical capabilities to get you started.
For instance, it can calculate summary statistics, correlation, regression and random sampling. The table below contains some simple data to play around with.
CREATE TABLE stats (
sample_id SERIAL PRIMARY KEY,
x INT,
y INT
);
INSERT INTO stats (x,y)
VALUES
(1,2), (3,4), (6,5), (7,8), (9,10);
You can find the mean, variance and standard deviation using the functions below:
SELECT
AVG(x),
VARIANCE(x),
STDDEV(x)
FROM stats;
You can also find the median (or any other percentile value) using the percentile_cont function:
-- median
SELECT
PERCENTILE_CONT(0.5)
WITHIN GROUP (ORDER BY x)
FROM stats;
-- 90th percentile
SELECT
PERCENTILE_CONT(0.9)
WITHIN GROUP (ORDER BY x)
FROM stats;
Another trick lets you calculate the correlation coefficients between different columns. Simply use the corr function.
SELECT
CORR(x,y)
FROM stats;
PostgreSQL lets you run linear regression (sometimes called the most basic form of machine learning) via a set of inbuilt functions.
SELECT
REGR_INTERCEPT(x,y),
REGR_SLOP(x,y),
REGR_R2(x,y)
FROM stats;
You can even run Monte Carlo simulations with single queries. The query below uses the generate_series and random number functions to estimate the value of π by randomly sampling one million points inside a unit circle.
SELECT
CAST(
COUNT(*) * 4 AS FLOAT
) / 1000000 AS pi
FROM GENERATE_SERIES(1,1000000)
WHERE CIRCLE(POINT(0.5,0.5),0.5) @> POINT(RANDOM(), RANDOM());
Work with shape data
Another unusual data type available in PostgreSQL is geometric data.
That's right, you can work with points, lines, polygons and circles within SQL.
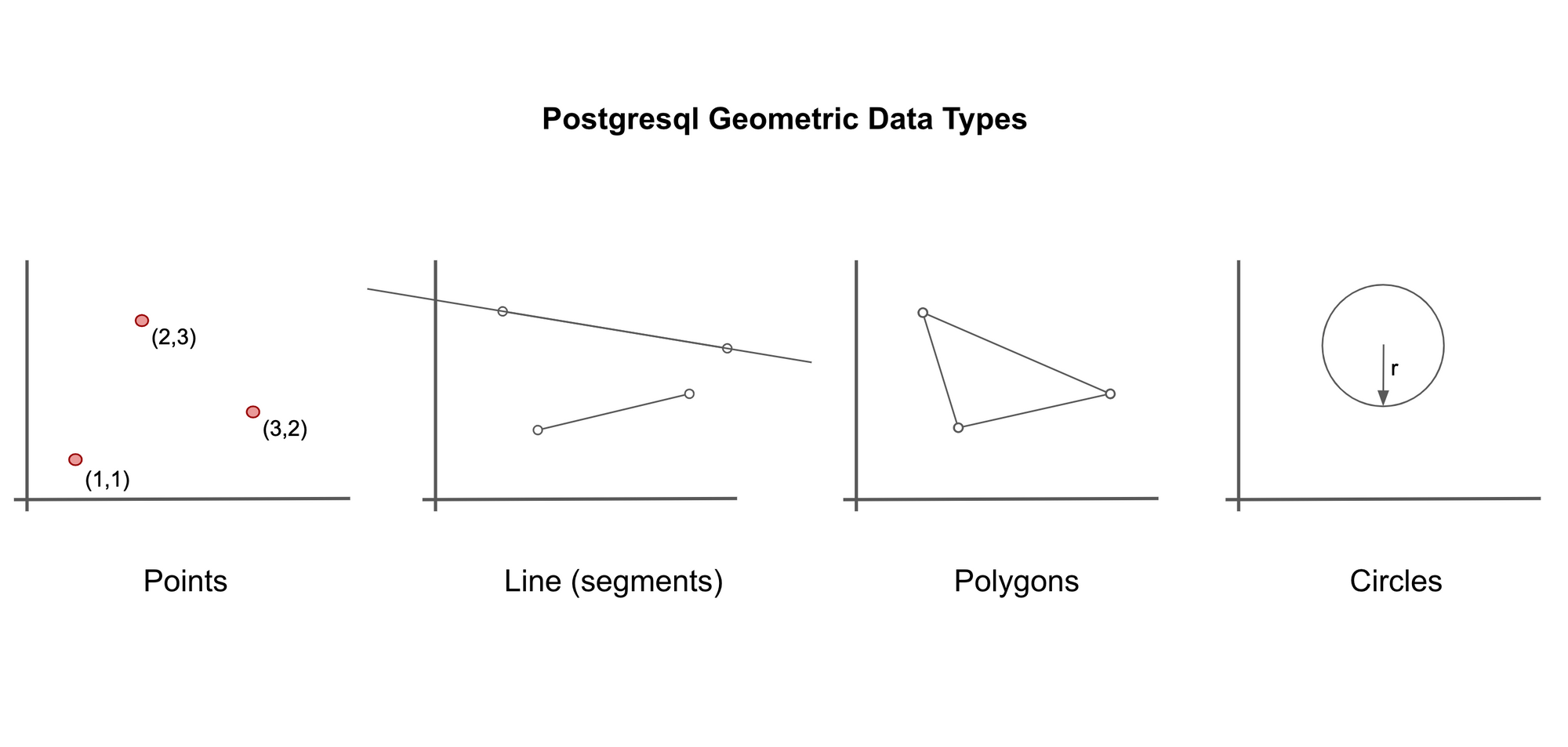
Points are the basic building block for all geometric data types in PostgreSQL. They are represented as (x, y) coordinates.
SELECT
POINT(0,0) AS "origin",
POINT(1,1) AS "point";
You can also define lines. These can either be infinite lines (specified by giving any two points on the line). Or, they can be line segments (specified by giving the 'start' and 'end' points of the line).
SELECT
LINE '((0,0),(1,1))' AS "line",
LSEG '((2,2),(3,3))' AS "line_segment";
Polygons are defined by a longer series of points.
SELECT
POLYGON '((0,0),(1,1),(0,2))' AS "triangle",
POLYGON '((0,0),(0,1),(1,1),(1,0))' AS "square",
POLYGON '((0,0),(0,1),(2,1),(2,0))' AS "rectangle";
Circles are defined by a central point and a radius.
SELECT
CIRCLE '((0,0),1)' as "small_circle",
CIRCLE '(0,0),5)' as "big_circle";
There are many functions and operators that can be applied to geometric data in PostgreSQL.
You can:
- Check if two lines are parallel with the
?||operator:
SELECT
LINE '((0,0),(1,1))' ?|| LINE '((2,3),(3,4))';
- Find the distance between two objects with the
<->operator:
SELECT
POINT(0,0) <-> POINT(1,1);
- Check if two shapes overlap at any point with the
&&operator:
SELECT
CIRCLE '((0,0),1)' && CIRCLE '((1,1),1)';
- Translate (shift position) a shape using the
+operator:
SELECT
POLYGON '((0,0),(1,2),(1,1))' + POINT(0,3);
And lots more besides - check out the documentation for more detail!
Use recursive queries
Recursion is a programming technique that can be used to solve problems using a function which calls itself. Did you know that you can write recursive queries in PostgreSQL?
There are three parts required to do this:
- First, you define a starting expression.
- Then, define a recursive expression that will be evaluated repeatedly
- Finally, define a "termination criteria" - a condition which tells the function to stop calling itself, and return an output.
The query below returns the first hundred numbers in the Fibonacci sequence:
WITH RECURSIVE fibonacci(n,x,y) AS (
SELECT
1 AS n ,
0 :: NUMERIC AS x,
1 :: NUMERIC AS y
UNION ALL
SELECT
n + 1 AS n,
y AS x,
x + y AS y
FROM fibonacci
WHERE n < 100
)
SELECT
x
FROM fibonacci;
Let's break this down.
First, it uses the WITH clause to define a (recursive) Common Table Expression called fibonacci. Then, it defines an initial expression:
WITH RECURSIVE fibonacci(n,x,y) AS (
SELECT
1 AS n ,
0 :: NUMERIC AS x,
1 :: NUMERIC AS y...
Next, it defines the recursive expression that queries fibonacci:
...UNION ALL
SELECT
n + 1 AS n,
y AS x,
x + y AS y
FROM fibonacci...
Finally, it uses a WHERE clause to define the termination criteria, and then selects column x to give the output sequence:
...WHERE n < 100
)
SELECT
x
FROM fibonacci;
Perhaps you can think of another example of recursion that could be implemented in PostgreSQL?
Final remarks
So, there you have it - a quick run through of some great features you may or may not have known PostgreSQL could provide. There are no doubt more features worth covering that didn't make it into this list.
PostgreSQL is a rich and powerful programming language in its own right. So, next time you are stuck figuring out how to solve a data related problem, take a look and see if PostgreSQL has you covered. You might surprised how often it does!
Thanks for reading!