
By Faizan Ahmed
Search isn’t only about finding stuff.
Rather, search is always the start of a larger journey. Search can be the start of reconnecting with someone, the beginning of a purchase, or discovering crucial information and new opportunities.
Our expectations for search have gotten higher and higher since Google has gotten better and better. These days, very few people search beyond the first page. If those search results aren’t good enough, they’ll either try again or they’ll quit. As Search Engine Watch reports, “Page 1 results garnered 92 percent of all traffic from the average search, with traffic dropping off by 95 percent for Page 2.”
Search becomes an issue for the software when there is a huge amount of data. By the time your database is huge enough to have problems that require search, your company will likely be equally large. It’s not a particularly burning problem for companies or platforms just starting up. But it will be a growing pain. Brace yourselves and keep this in your product road map.
For companies that are building or maintaining a search feature, you already understand why it’s important to make search immediate, helpful, and robust for users. In a lot of these cases, search can be seen as the start of a conversation the user has with software. At Flipp, our search enables users to search through ecommerce and digital flyer items. Most of the time, it’s actually literally the first thing most people use…
Search Makes the First Impression
The first impression is not the last impression, but a lasting impression.
— Anonymous
Most of the time, when someone downloads the Flipp app, the first thing they do is search. Before even looking at the menu for retailers, they search for the name of their favorite store. Such as “Wal-Mart”.

If that person isn’t happy with the search functionality, they’ll stop using the app right there. That user churns shortly after signing up.
This tendency to go to search first is completely organic for our app, as I’m sure it is for many others. We hadn’t even mentioned search in our on-boarding! Once we noticed this tendency, we decided to add an overlay in the on-boarding process. New users can better understand and leverage search. We’re making that feature right now!
Search is also very important for retaining users. If I was consistently unable to find retailers or specific items I was looking for, I’d get frustrated.
The worst thing your search could do is to produce a blank page. And the easiest thing to do with an app is delete it.
You want to display results. Can you imagine Google not turning up a result for the vast majority of their keywords? You’ll notice that even if you don’t find something that exactly matches your Google search, they will find something to show you. And their system is set up so well that you will likely find the thing you meant to find after a couple of links or searches.
There are a couple of keys to avoiding blank pages:
- You could start by correcting the user’s misspells or mistakes for them (“Did you mean…?”). You could also autocorrect it on their behalf.
- Make sure you identify their intent. What did they mean to search for? What is the problem they’re trying to solve with that query? Is there an alternative way of phrasing it or an alternate route to the solution?
At a bare minimum, you must show them something that you think they might find interesting.
The keys to populating the search page, and ultimately finding what the person is looking for in the search database, requires tying two elements together: retrieval and relevance.
What is Retrieval?
The process of retrieval means sorting through the entire search database and narrowing the search down to a more specific set of items.
At Flipp, this means going from thousands of items down to the 100 items most likely to match the person’s search. We use Apache Solr, which indexes all items and merchants in a caching layer.
Solr requires that the Flipp team inputs the item name and attributes. For example, it could look like this:

Solr indexes each item and their respective fields, and searches against all those fields to bring up the item that matches your query the most. In that particular example, we used the “item name” and “brand” name and “merchant”. But it could be the “category,” “description,” and many other different attributes.
Sounds simple enough, right?
Search gets complicated very quickly.
For example, if someone types in “TV” into search, they’d be expecting to see an actual television screen. The problem is there are a lot of accessories for TVs — tables, shelves, displays, mounts, and so on…
The user wants to see a TV screen, so these accessories wouldn’t be relevant. We’d have to make sure Solr understands the search intent when retrieving items for the user. For this purpose Solr utilizes the following mechanisms:
- Boosting. This is the process of weighing each of the items attributes so that one attribute has precedence over the other. For example, a product’s name is given more weight than its description.
- Synonyms. These are words which mean the same product but are spelled or referred to differently. A good example would be “tv” and “television”. When queried, Solr should fetch the same results for both terms.
- Tokenization. This refers to tokenizing a word and generating word parts based on various delimiters. For example there should be no difference in results fetched for queries like “X-box”, “X box” or “XBox.”
What is Relevance?
After the retrieval process has pulled the 100 items from the thousands of items, the relevance process follows. The relevance process decides how to sort these 100 items from the database. It determines the order.
Which do we display first?
Keep in mind the stat we talked about at the beginning of the piece. It indicates that most people don’t look past the first ten items.
Even though the Flipp app doesn’t have pagination, we noticed that most people don’t look past the first few items. We curate this item order according to the user’s preferences or signals received for user behavior. To do that, we use four different algorithms:
Crowd curation
This is a factor that sorts items by popularity at this moment. Items that have the most clicks by users in the past 30 days get placed at the top. We assign greater weight by recency. My colleague Thanesh writes more about crowd curation here.
Category curation
This is a factor that sorts items by category. For example, hypothetically, “TV” maps to “electronics” and “home entertainment systems.” There will be times when the user wants to see related items, and other times they don’t, so we don’t want to disqualify this factor completely. Item categories that match the category of the search query get bumped up.
For example, a search for “TV” would display items in “TV/home entertainment systems,” up higher, and items tagged as “accessories” lower. Without category curation, TV accessories would be lumped in with TV screens, and we would have to limit retrieving those items, which would exclude the users interested in both accessories and screens.
The first two images below display the effect of category curation whereby a query for “oranges” would also show orange juices as a result, however after applying category curation (3rd image) we see that only oranges are bumped up as a result.
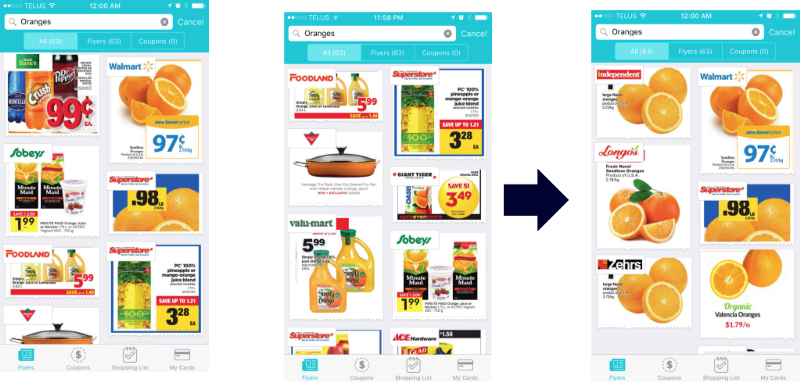
Solr Score casts relevance as a probability problem. A relevance score ought to reflect the probability a user will consider the result relevant, probabilistic information retrieval. For those interested in how this scoring is done can refer to details here.
The cumulative score of an item gets calculated by scaling and accumulating the individual crowd and category curation scores plus the Solr Score.
Negative Terms Post Processing refers to bumping down negative terms associated with search queries. The search results which contain these negative terms are either not retrieved or shown at the very end of the ranked search results.
For instance “Coffee” is a popular search term. By default, a search for coffee would also get some popular coffee tables. We would set the word “table” in “coffee table” as a negative term. Because people looking for coffee probably aren’t looking for living room decor. This bumps down all the coffee tables in the search results.
Final Thoughts
It’s funny how something as simple as search can quickly get so complicated. This is just a small sliver of the thought that goes into our search and our product. Thanks for reading! Hopefully you can use some insights from the retrieval and relevance processes to improve your software’s search.
On a related note, this might give you an idea of why things like filter bubbles emerge when it comes to search engines. We’re trying to help you find what you want. And because of most people’s limited attention, we don’t have time to show you things you might not want.
I’m Faizan, a data engineer at Flipp. If you’re interested in reinventing the way people buy things, have a look at our engineering blog and our current job postings.