
By Daitan
By Bruno Schionato, Diego Domingos, Fernando Moraes, Gustavo Rozato, Isac Souza, Marciano Nardi, Thalles Silva — Daitan Group
Last time, we talked about how to deploy Machine Learning (ML) models to production using AWS Lambda. Following our plans, we give a step further and investigate more complete solutions. In this post, we turn our attention to Amazon SageMaker.
SageMaker is a platform for developing and deploying ML models. It promises to ease the process of training and deploying models to production at scale.
To accomplish this goal, it offers services that aim to solve the various stages of the data science pipeline such as:
- Data collection and storage
- Data cleaning and preparation
- Training and tuning ML models
- Deploy to the cloud at scale
With that in mind, SageMaker positions itself as a fully managed ML service.
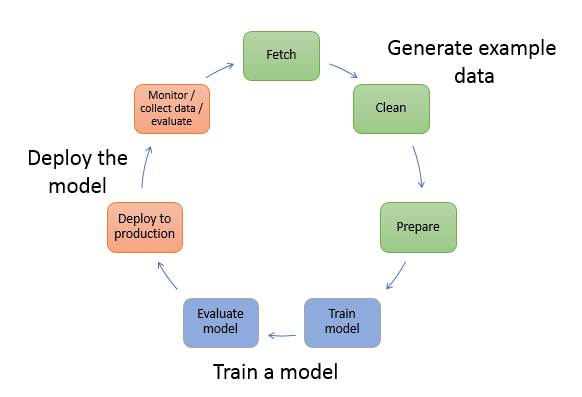
The typical workflow for creating ML models involve many steps. In this context, SageMaker aims to abstract the process of solving each one of these stages. In fact, as we will see, by using SageMaker’s built-in algorithms, we can deploy our models with a simple line of code.
 _Image Credits: [SageMaker website.](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html" rel="noopener" target="blank" title=")
_Image Credits: [SageMaker website.](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html" rel="noopener" target="blank" title=")
The process of training, evaluating and deploying is all done using Jupyter notebooks. Jupyter notebook brings many advantages. It gives freedom for experienced data scientists who are already accustomed to the tool. Besides, it also offers flexibility for those that do not have much experience in the area.
In summary, SageMaker provides many benefits for anyone that would like to train and deploy ML models to production. However, the price can be an issue.
Generally, the price depends on how and where you use Amazon’s infrastructure. For obvious reasons, normal machine instances have lower costs than GPU capable instances. Note that different regions have different prices. Also, Amazon groups the machines for different tasks: building, training, and deploying. You can find the full price chart here.
For training, SageMaker offers many of the most popular built-in ML algorithms. Some of them include K-Means, PCA, Sequence models, Linear Learners and XGBoost. Plus, Amazon promises outstanding performance on these implementations.
Moreover, if you want to train a model using a third party library like Keras, SageMaker also gets you covered. Indeed, it supports the most popular ML frameworks. Some of them include:

Checkout these examples using Tensorflow Estimators API and Apache MXNet.
SageMaker — a brief Overview
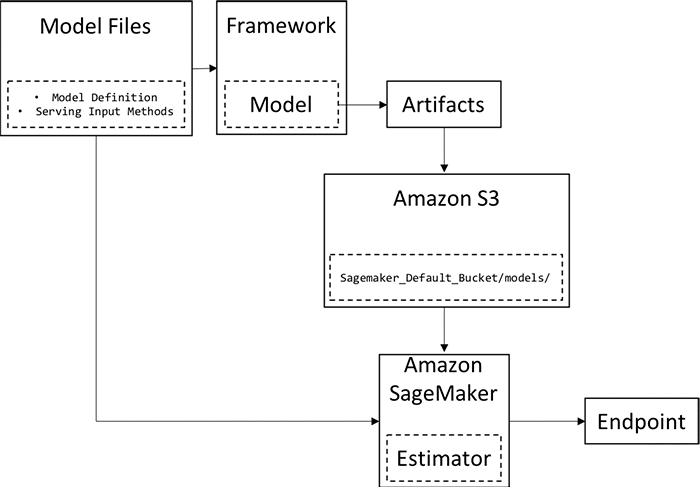
To understand how SageMaker works, take a look at the following diagram. Let’s say you want to train a simple Deep Convolution Neural Network (CNN) using Tensorflow.
 _Image Credits: [SageMaker website](https://aws.amazon.com/blogs/machine-learning/bring-your-own-pre-trained-mxnet-or-tensorflow-models-into-amazon-sagemaker/" rel="noopener" target="blank" title=").
_Image Credits: [SageMaker website](https://aws.amazon.com/blogs/machine-learning/bring-your-own-pre-trained-mxnet-or-tensorflow-models-into-amazon-sagemaker/" rel="noopener" target="blank" title=").
The first box “Model Files” represents the CNNs definition files. This is your model’s architecture. Convolutions, pooling, and dense layers, for instance, goes there. Note that, here, it is all developed using the framework of choice — Tensorflow in this case.
Second, we proceed by training the model using that framework. To do that, Amazon launches ML compute instances and uses the training code and dataset to carry out the training process. Then, it saves the final model artifacts and other output in a specified S3 bucket. Note that we can take advantage of parallel training. This can be done via instance parallelism or by having GPU capable machines.
Using the model’s artifacts and a simple protocol, it creates a SageMaker model. Finally, this model can be deployed to an endpoint with options regarding the number and type of instances at which to deploy the model.
SageMaker also has a very interesting mechanism for tuning ML models — the Automatic Model Tuning. Usually, tuning ML models is a very time and computational consuming task. The reason is that the available techniques rely on brute-force methods like grid-search or Random Search.
To give an example, using Automatic Model Tuning, we can select a subset of possible optimizers, say Adam and/or SGD, and a few values for the learning rate. Then, the engine will take care of the possible combinations and focus on the set of parameters that yields the best results.
Also, this process scales. We can choose the number of jobs to run in parallel along with the maximum number of jobs to run. After that, Auto Tuning will do the work. This feature works with both third-party libraries and built-in algorithms. Note that Amazon provides Automatic Model Tuning at no extra charge.
How about using SageMaker’s deployment capabilities to serve a pre-trained model? That is right, you can either train a new model using the Amazon Cloud or use it to serve a pre-existing model. In other words, you can take advantage of the serving part of SageMaker to deploy models that were trained outside it.
Training and Deploying on SageMaker
As we know, SageMaker offers a variety of popular ML estimators. It also allows the possibility to take a pre-trained model and deploy it. However, based on our experiments, it is much easier to use its built-in implementations. The reason is that to deploy third-party models using the SageMaker’s APIs, one needs to deal with managing containers.
Thus, here we pose the challenge of dealing with the complete ML pipeline using SageMaker. We will use it from the most basic to the more advanced ML tasks. Some of the tasks involve:
- Uploading the dataset to an S3 bucket
- Pre-processing the dataset for training
- Training and deploying the model
Everything is done in the cloud.
Like in the previous post, we are going to fit a linear model using the KDD99 intrusion dataset. You can find more details about the dataset and pre-processing steps in this article.
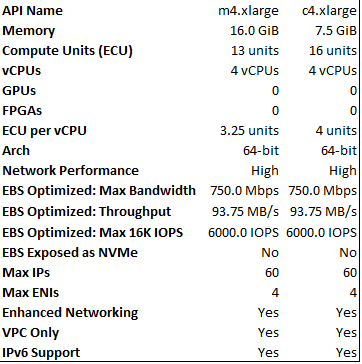
All the process of training and deploying the model is done using SageMaker’s Jupyter notebook interface. It does not need any configuration and the notebook runs on an EC2 instance of your choice. Here, we chose an ml.m4.xlarge EC2 instance for hosting the notebook. We had problems loading the KDD99 dataset using a less powerful instance (due to lack of space).
Take a look at the EC2 machines’ configurations:
To fit linear models, SageMaker has the Linear Learner algorithm. It provides a solution for both classification and regression. With very few lines, we can define and fit the model on the dataset.
Take a look at the Estimator class. It is a base class that encapsulates all the different built-in algorithms from SageMaker. Among other parameters, some of the most important ones include:
- image_name: The container image to use for training.
- train_instance_count: Number of EC2 instances used for training.
- train_instance_type: The type of EC2 instance to use for training.
- output_path: S3 location for saving the training result.
To define which kind of model we want to use, we set the ‘image_name’ parameter to ‘linear-learner’. To execute the training procedure, we picked a ml.c4.xlarge EC2 instance. It has 4 virtual CPUs and 7.5 GB of RAM.
The model’s hyper-parameters include:
- feature_dim: the input dimensions
- predictor_type: if classification or regression
- mini_batch_size: how many samples to use per step.
Finally, SageMaker provides a very alike scikit-learn’s based API for training. Just call the fit() function, and you are in business.
Now comes the final part — deployment. To do it, much like when training, we just run one line of code.
This routine will take care of deploying the trained model to an Amazon endpoint. Note that we need to specify the type of instance we want, in this case, a ml.m4.xlarge EC2 instance. Also, we can define a minimum number of EC2 instances to deploy our model. To do that, we just set the _initial_instancecount parameter to a value greater than 1.
Auto Scaling
We have two main goals with the tests.
- To evaluate the complete ML pipeline offered by SageMaker
- To assess training and deploying scalability.
In all tests, we used the SageMaker Auto Scaling tool. As we will see, it helps to control the traffic/instances trade-off.
As stated on the AWS website:
AWS Auto Scaling monitors your applications and automatically adjusts capacity to maintain steady, predictable performance at the lowest possible cost.
In short, SageMaker Auto Scaling makes it easier to build scaling plans for various resources across many services. These services include Amazon EC2, Spot Fleets, Amazon ECS tasks, and more. The idea is to adjust the number of running instances in response to changes in the workload.
It is important to note that Auto Scaling might fail in some situations. More specific, when your application suffers some kind of spikes in traffic, Auto Scaling may not help at all. We know that for new (EC2) instances, Amazon needs some time to set up and configure the machine before it is able to process requests. Based on our experiments, this setup time might take from 5 to 7 minutes. If your application has small spikes (let’s say 2 to 4 minutes) in the number of incoming requests, by the time the EC2 instance setup time finishes, the need for more computing power might be over.
To address this situation, Amazon implements a simple policy to scale new instances. Basically, after a scaling decision takes place, a cool down period has to be satisfied before another scale activity occurs. In other words, each action to issue a new instance is interleaved by a fixed (configurable) amount of time. This mechanism aims to ease the overhead to launch a new machine.
Also, if your application has well defined/predictable user traffic, Auto Scaling might also be a bad choice. Suppose, you host an application’s website. You know that at a specific time, applications will be open for hundreds of millions of users. In this situation, the time required for Auto Scaling to be properly setup may end up in a poor user experience.
Results
We used Tauros and JMeter to run load tests on our ML model developed with Amazon SageMaker.
The first scenario is defined as follows:
- Number of concurrent users: 1000
- Ramp-up time of 10 minutes
- Hold-for period of 10 minutes
Simply put, the test consists of issuing requests from 1000 parallel users. In the first part of the test (first 10 minutes) the number of users is scaled from 0 to 1000 (ramp up). After, the 1000 users continue to send parallel requests for 10 more minutes (hold for period). Note that each user sends requests in a serial manner. That is, to issue a new request, a user has to wait until the current one finishes.
For the first tests, we decided to use a single machine. As a result, we did not define any scaling plan that would spawn new instances upon reaching some criterion.
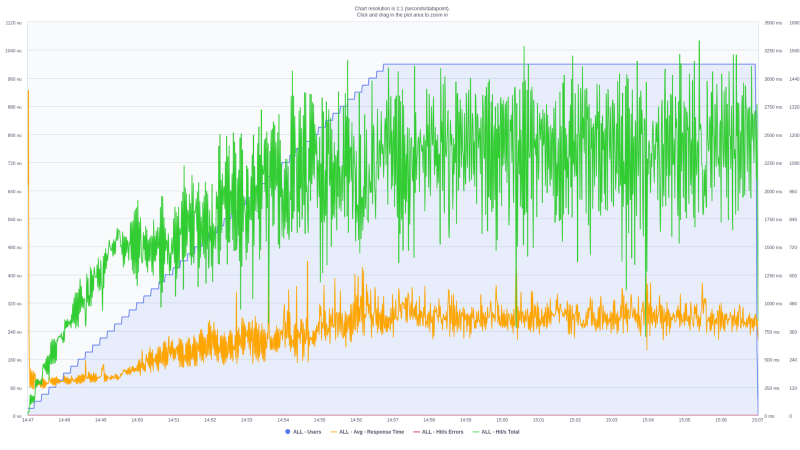
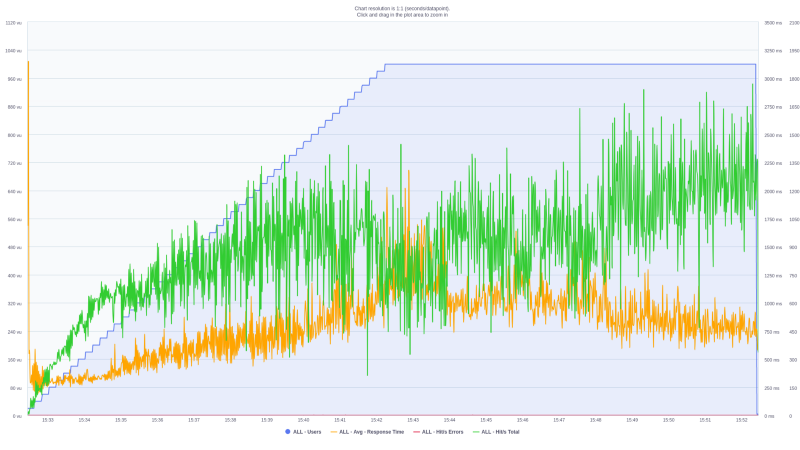
In the graph below, the blue line (increasing in a staircase shape) is the number of parallel users. The orange line represents the average response time, and the green line the number of requests.
![]()
In the beginning, the number of users scales from 0 to 1000. As expected, the number of issued requests to the model increases in a similar fashion.
In the last part of the experiment (last 10 minutes), the number of hits/requests and the mean response time stays steady. This suggests that this single machine seems to be capable of dealing with the current payload.
Also, this single machine was able to process an overall average request of 961.3 hits/sec. Actually, after reaching the max number of simultaneous users (1000), this average was nearly 1200 requests/second.
To further access our hypothesis, we decided to add a scaling plan to our loading tests. Here, when the number of parallel requests/minute reaches the 30k mark, we instruct the system to scale up the number of running instances. For all tests, the maximum number of instances was set to 10. However, in all cases the SageMaker Auto Scaling did not use all the available resources.
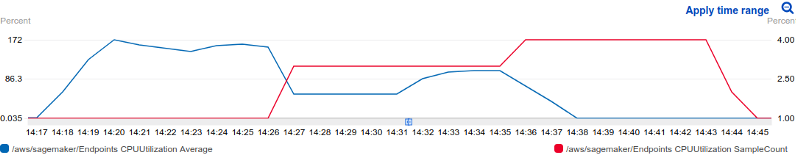
For the test below, Amazon Auto Scaling only issued 1 more instance to help processing the current payload. That is represented by the red line in the CPU utilization figure below.
![]()

Nevertheless, the addition of this new instance was able to increase the throughput and reduces latency. This is noticeable after the 15:48 time mark.
To better access the Auto Scaling tool, we decided to reduce the threshold number of requests/minute before scaling. Now, Auto scaling is advised to launch a new instance as soon as the throughput reaches 15k requests/minute. As a consequence, Auto Scale used a total of 4 instances to match the scaling plan. It is also quite intuitive to see that as the number of instances grow, the CPU percent usage decreases.
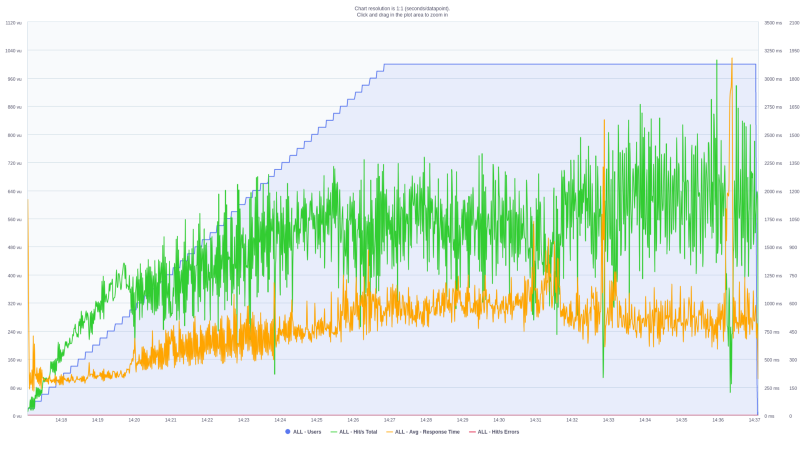
![]()
We noticed that at the beginning of all tests, we had a big spike in latency. Our experiments suggest this high average value is caused by the test itself (Taurus/JMeter) warming up and preparing resources. Note that after the spike, the response time quickly decreases to normal values. Later, it increases along with the number of virtual users (as expected). Also, this initial spike is not seen in the latency statistics for the API Gateway or SageMaker — which supports our initial thoughts.
Also, specifically for this test and choice of model, Auto Scale was not very effective. The reason is that the amount of load we are performing to the server is completely handled by a single machine.
Conclusion
Here are a few of our observations about SageMaker:
- It offers a very clean and easy to use interface. Jupyter notebooks offer many advantages and the built-in algorithms are easy to use (scikit-learn based API). Also, the machines used for training are only billed when training is happing. No payment for idle time :)
- It takes away many of the boring tasks of ML. Auto-scaling and auto hyper-parameter tuning are excellent features.
- If using the built-in algorithms, deployment is very straight-forward. Just one line of code.
- Through SageMaker supports third-party ML libraries, we found that to serve a pre-trained model is not as straightforward as using their native API.