
By Daitan
Moving machine learning (ML) models from training to serving in production at scale is an open problem. Many software vendors and cloud providers are currently trying to properly address this issue.
One of the biggest challenges is that serving a model (i.e. accepting requests and returning a prediction) is only part of the problem. There is a long list of adjacent requirements. These include, for example:
- Model versioning
- Retraining (automatically or on-demand)
- Preprocessing input before predictions
- Scaling infrastructure on-demand
In order to better advise our teams in that respect, we have set up a small, but smart and dedicated, research group here at Daitan Group.
To begin, we have established a roadmap for learning the requirements and caveats of deploying machine learning models into multiple ML pipelines and infrastructures.
The purpose of this article is to provide an overview of our methodology and the results we achieved from our baseline implementation.
Creating a Baseline
Amazon SageMaker, Google Cloud ML, Seldon Core, and others promise a smooth, end-to-end pipeline from training to serving at scale. However, before working with such solutions we wanted to get our hands dirty with a manual process to create a baseline reference.
The goal was to train, export, and serve at scale an ML model in the cloud with the least possible effort.
To start, we chose TensorFlow as our ML framework and AWS Lambda as the deploying infrastructure. We used Apache JMeter and Taurus to generate load tests.
Our baseline was predicated on experimenting with the following combinations:
- A lightweight ML model
- In different configurations of AWS Lambda
- Using two popular programming languages — Python and Java
With some combinations, we reached ~40 predictions per second with an average response time of ~200ms. Such results would address many production use cases. And we could effortlessly scale up, if needed.
However, there were caveats, which we discuss below when we detail the test results.
Furthermore, a second experiment with a “heavier” model (image segmentation model) was completed, which will be detailed in a follow-up post.
Why TensorFlow and AWS Lambda?
TensorFlow is an open-source library created by Google for programming data flows across a range of tasks. We started with TF for a number of reasons:
- It is currently the most popular machine learning framework on GitHub with around 110k stars and 1.6k contributors
- It accumulates a number of success stories and is available in multiple platforms
- It is getting better and better as a broad framework for ML, not only for deep learning
These factors, combined, make TF a natural candidate for our clients to use when building predictive models.
AWS Lambda is Amazon’s implementation of the Function-as-a-Service (FaaS) or Serverless architecture. We have noticed a significant increase in use over the last few years.
Some of its most avid users include companies like Netflix and Coca-Cola. Recent studies (below) show that this dominance is likely to continue for the coming years.

Most of the popularity comes from the versatility and flexibility of FaaS to deploy applications. Also, they reduce operational costs and are easy to use because most of the complexity is hidden from the end-user.
Another important point in favor of AWS Lambda is its pay-per-execution pricing. For example, in a single setup, all our tests described below only cost approximately one dollar. As a result, it can be suitable for a wide range of cost-effective, event-driven applications.
Yet, when using AWS Lambda to serve ML models in production, you need to take care of all the steps in the total pipeline. These steps typically include:
- Training
- Testing
- Versioning
- Deploying
- Publishing the new ML model version
If not properly automated, these tasks may contribute to higher-than-planned costs and a slower pipeline.
In a series of upcoming articles, we will explore how other ML pipelines facilitate the steps above, comparing with using AWS Lambda only.
Training our Machine Learning Model
Overall, we wanted to investigate the performance of various platforms for serving ML models at scale.
In this direction, our first experiments focused on deploying a simple machine learning model. This choice provided major benefits, especially eliminating the time and concerns over the model training and performance.
To train our model, we chose the KDD99 dataset. The dataset has a total of 567,498 records, with 2211 of those considered anomalies.
After checking for missing values, we proceeded by splitting the current corpus into training and testing sets. We then normalized the training data using the Mean Standardization technique.
Next, we trained a binary Logistic Regression model on the given problem. Finally, we assessed the model accuracy by calculating the confusion matrix:
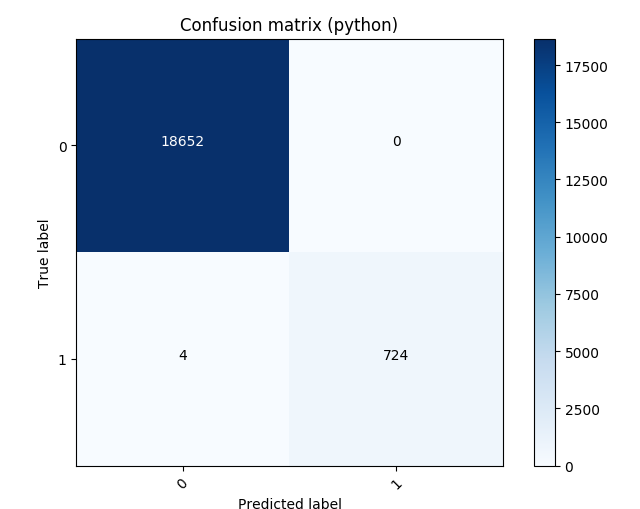
It is important to note that our focus lies in the infrastructure side for serving ML models. Thus, the best practices for training ML algorithms is out of our scope.
Setting up the Environment
To get things done more quickly, we used some popular AWS services. They included the API Gateway, Lambda functions, S3, Cloudwatch, and IAM.
The following describes the role for each:
- API Gateway is the entrance door to send requests to our model. It handles the client’s HTTP requests and triggers events as requests arrive.
- Lambda functions are triggered by such requests. In a nutshell, the code inside a Lambda function is responsible for running our ML inference functions.
- We use S3 to store files like models and libraries.
- Cloudwatch is responsible to get the logs generated by our Lambda functions.
- IAM provides the infrastructure to control authentication and authorization in our application.
Designing Load Tests
We designed the tests to answer questions regarding the best cost-benefit when using AWS Lambda services. In this context, our tests focused on three main components:
- The exploration of different memory (machine) capacities
- The performance of different programming languages
- Different strategies for loading a model into a Lambda function
We used Java and Python. To make the tests more comparable, we designed both implementations to be as similar as possible.
In summary, the Python and Java code that goes inside the Lambda executes the same operations. First, it unzips the file containing the metadata about the model. Second, it gets the input parameters ready. And finally, it performs model inference.
One nice feature of AWS Lambda is that we can configure it to deploy our model with different amounts of memory. In other words, we can choose how much memory we allow the Lambda function to use. Moreover, when we increase this memory, CPU settings are also upgraded — meaning that we switch to a more powerful machine.
We chose three different configurations of memory in our load tests. For Python and Java, we performed the tests using the memory sizes of 256, 512 and 1024 Mb.
We ran each scenario using the following parameters:
Scenario 1: Progressive Requests per Minute
In this scenario, we send a single request and wait for M minutes to send the next one. At the beginning of the test (minute 0), the load test framework sends a single request to the Lambda. Next, it waits for 6 minutes and sends a new request. Continuing, it waits 10 minutes more to issue the next request, and so on. In total, the test takes roughly one hour and requests are performed at minutes 0, 6, 16, 31, and 61.
The purpose is to assess how much time a Lambda function instance will be kept alive before going down. As we know, each time AWS launches a new Lambda, it needs time to setup and install dependencies (cold-start). So, we want to evaluate how often this situation occurs for a single instance.
In short, a cold-start may occur in two situations.
- When we invoke a Lambda function for the first time
- When the Lambda is not used for an extended period of time
In the second case, after an idle timeout, the Lambda goes down. As a result, subsequent requests need new cold-starts, which accounts for an increased setup latency.
Scenario 2: Parallel Request Evaluation
In this scenario, we played with different users performing concurrent requests. To begin, we set up the concurrency parameter to C = 9. It means that there will be 9 different users making requests for a T period of time. This T period is the sum of an R period (ramp-up in minutes) and an H period (hold-for in minutes).
The ramp-up period means that a new user will start making requests after a period of R/C time. At the end of this ramp-up time, all 9 users have joined the system and started making requests.
The hold-for period means that the 9 users (making parallel requests) will be kept for H minutes. We setup R equal to 3 and H to 1 at the first stage.
After that, C was set to 18, meaning that 9 new users will “join the system” and start making requests, R is then set to 0 and H to 1 minute.
We aimed to answer two questions with this test. We wanted to see the response time of new users making requests and its impact when new Lambda instances need to be instantiated (cold-starts).
Results and Discussion
The first graph shows the results of the first test scenario. Here, given a period of time, we perform requests to an AWS Lambda instance in different rates. Only one user — one parallel request is made throughout the test.
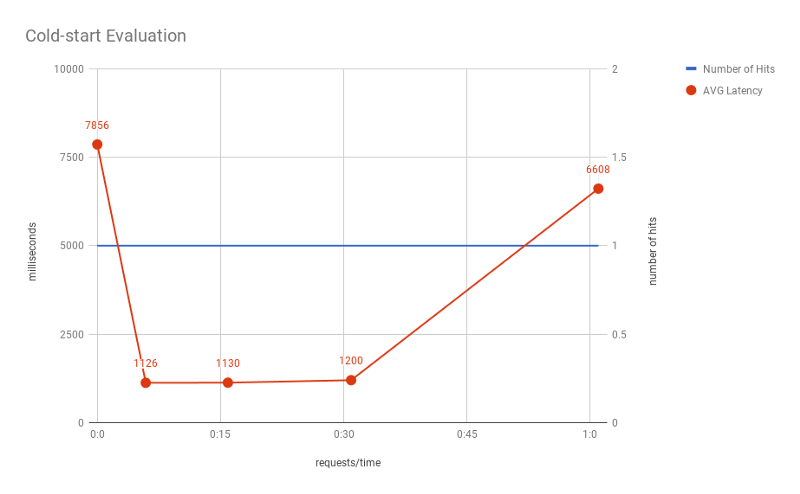
As expected, the first user/request presented a much longer response time. Almost 8 seconds for the cold-start. Passed 5 minutes from the first request, we can see that AWS used the same Lambda instance, which caused a very small response time (only 1 second).
Interestingly, even with longer intervals between requests, AWS managed to use the same instance. Specifically, requests after 10 and 14 minutes after the previous one still used the same Lambda. However, for a time interval of 30 minutes, AWS had to spin a new Lambda — which resulted in a longer response time due to cold-start (nearly 6 seconds). In practice, AWS had to shut down the Lambda somewhere in the interval of 14 to 30 minutes.
Again, our goal was to assess how long AWS maintains a Lambda instance alive. In practice, AWS does not guarantee it. In fact, AWS algorithms might decide this time based on many other circumstances such as network load and so on. However, this test helped us further understand how AWS Lambda internal logic works.
For the second test scenarios, we have the following settings.
For all the experiments, we display 4 types of information.
- The total number of hits (requests) — blue line.
- The maximum latency — red line.
- The average latency — yellow line.
- The number of users at a given moment — green line.
The set of graphs below show the performance test comparisons between the two programming languages: Java and Python.
We increase the total number of users from 3 to 18 during a total testing time of 5 minutes (x-axis). The rate of users increasing is 3, 6, 9 and 18. Also, note that each user performs parallel requests to the server. So, when the number of users is 18, there can be up to 18 parallel requests being issued.
For further understanding, the y-axis to the left shows the results in milliseconds. Use this axis to evaluate the max and mean latency. In contrast, the y-axis to the right displays information about the number of hits and parallel users.
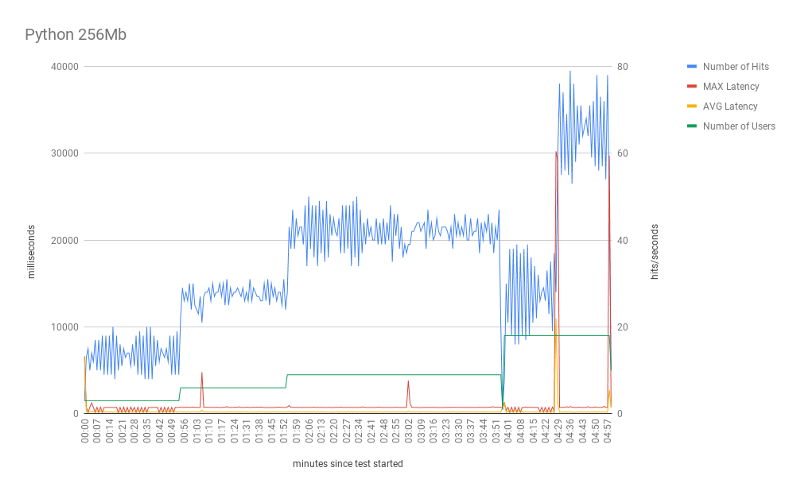
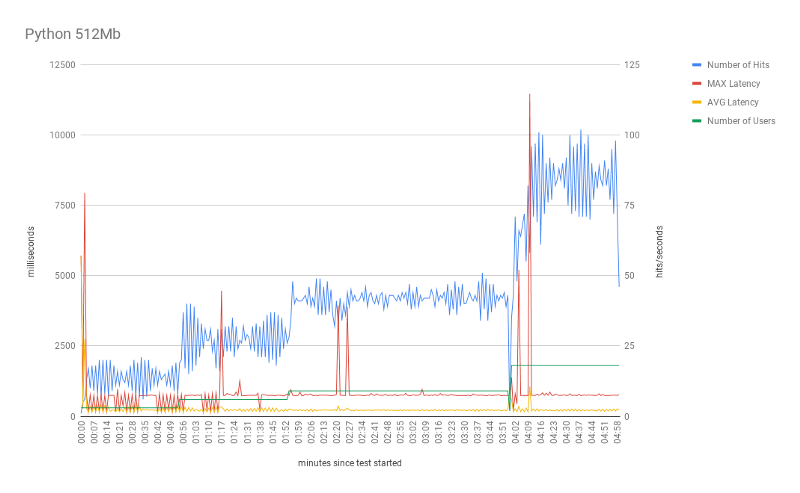
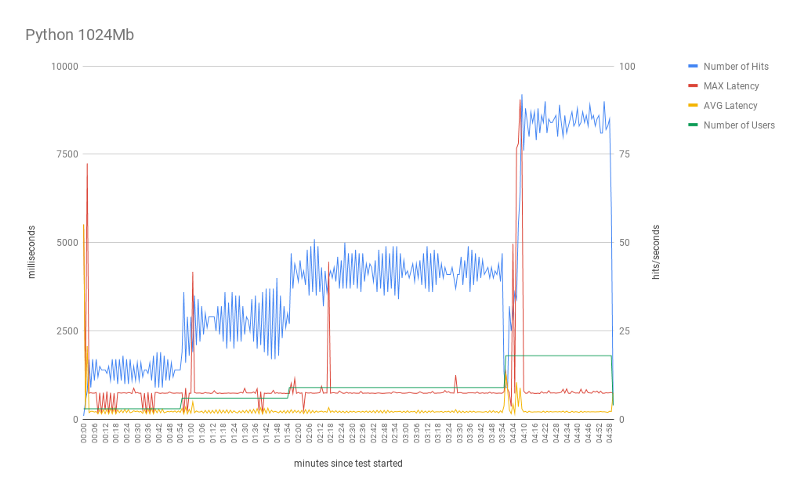

Overall, the tests using Python behaved as expected. Note that the number of parallel requests (hits) grows as the number of parallel users increases. One very interesting point is the effect of the cold-start in terms of the number of users.
First, the red line (max latency) shows the first spike at the beginning of every experiment. In practice, at the beginning of the experiment, AWS instantiates 3 Lambda instances. One for each user request. As we discussed, each request (from a new user), requires this setup. That is the cold-start.
Yet, we can see some other spikes in latency during the test execution. These spikes seemed to be related to the increase in the number of users (parallel requests). When we increase the number of users, AWS (again) needs to set up new Lambda functions for taking care of the new incoming requests. And as expected, subsequent requests, from the same user, are executed by the same Lambda instances. As a result, it avoids a new cold-start for each new request.
Another interesting point is the effect of the Lambda memory on the test scalability. With 256Mb, the test reaches a peak of 77 hits (with 18 parallel users) and mean hits of 33.4. This mark significantly increased when using 512Mb, but did not go any further with 1024Mb. Indeed, most of the statistics (avg response time, avg hits, and min response time) did not change much. Perhaps, the most significant improvement (from 512 to 1024 Mb) is the max response time, which indicates faster cold-starts. Our tests suggest that 512Mb is the best cost/benefit setup for this specific model.
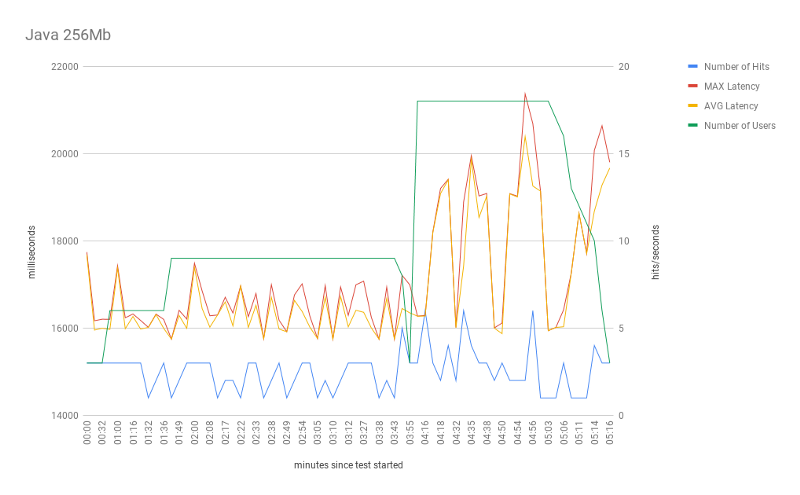
For Java, with the exception of the 256Mb settings, the overall performance was very similar to Python. To begin, the 256Mb test only scored a mean of 0.55 in the number of hits. Less than 1 request per second.
Actually, this test configuration was not able to scale the number of requests in terms of users. Moreover, it suffered from very high latency across all test times. Average response time stayed at of 17,049 milliseconds ~17 seconds!
One possible reason for this poor performance is the JVM memory footprint since other memory configurations did just fine.
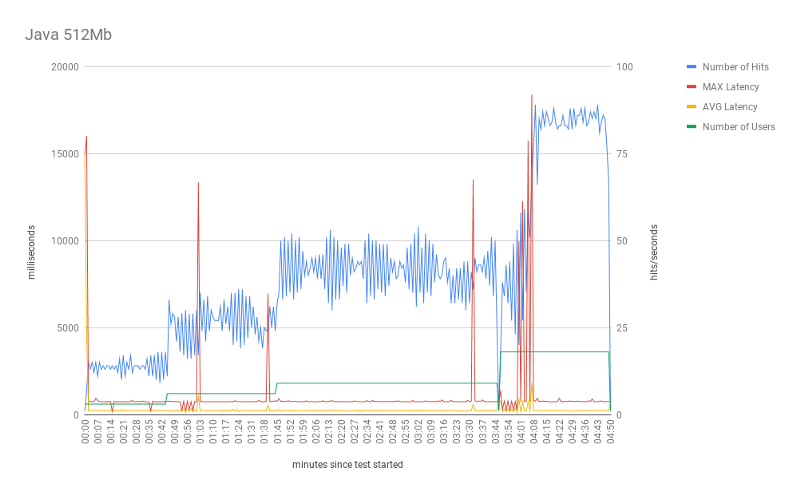
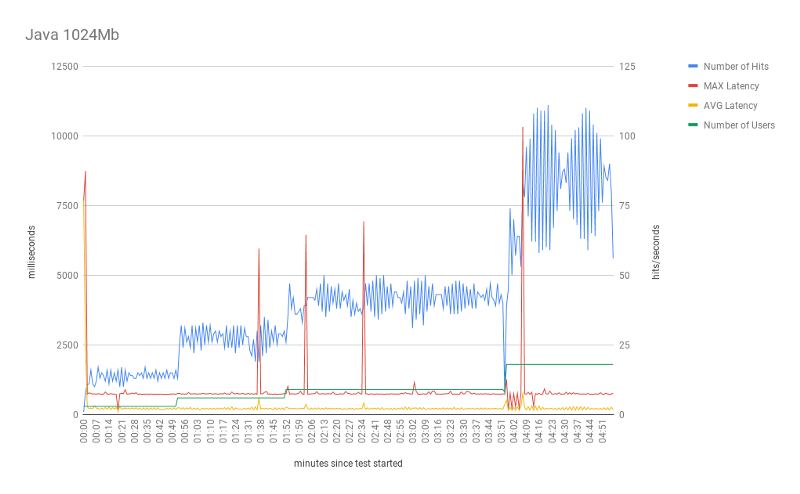

For 512 and 1024 Mbs, the results confirmed expected behavior. Comparing with the corresponding ones from Python, we can see very similar results.
One noticeable discrepancy, from Java 512 to Python 512, is the behavior of the max response time. For Java, response time was much higher, which translates to longer cold-starts.
Lastly, similarly to Python results, increasing the process memory size from 512 to 1024Mb did not achieve significantly better outcomes. Even though the number of hits didn’t improve very much, some cold-starts got a huge improvement. As shown in the table, the max response time for Java 512Mb was ~18s while for 1024Mb was ~10s.
Conclusion
In summary, AWS Lambda is a good choice for provisioning lightweight ML models that need to scale, with only a few caveats.
Among its main advantages for the use cases we envision are:
Convenience:
AWS Lambda is easy to deploy and auto-scale
AWS is a leader in the cloud market. Thus, many organizations are already deploying their applications and storing their data with them
Cost: depending on the workload, pay-per-execution can drive the infrastructure cost down.
Among the caveats, the language of choice of the Lambda function matters. Thus, it may have significant impacts on both performance and cost.
Also, if your application relies on very small latency, AWS Lambda might not be the best choice. The cold start penalty reduces the range of applications that can benefit from it. In general, one can extract the most from Lambdas if the application has either one of these attributes.
- A well defined and/or predictable traffic
- The cold start latency is not a problem to achieve the product requirements
In some situations, one could mitigate the cold start time with approaches like a ping to keep the Lambda functions up.
Another consideration is that TF models (even a simple model like the one used in this test) may not be the smallest option available in some situations.
Last but not least, any other step in the ML workflow such as versioning and retraining needs to be done by ourselves. This is expected since AWS Lambda is only a general-purpose computing environment.
Next Steps
Now we will try more advanced, end-to-end ML pipelines and compare the experience. The question is, will they provide us with a streamlined process from training to serving, with the flexibility and scalability we are looking for?
Stay tuned!
Authors
Bruno Schionato, Diego Domingos, Fernando Moraes, Gustavo Rozato, Isac Souza, Marciano Nardi, Thalles Silva — Daitan Group