
By Nick Harley
We all love to code.
When we think about coding, we are usually picturing ourselves building.
Building features, new innovations, new functionality, and exciting updates that users will love. It’s that mental picture that gets us excited about the things we can build next.
But the romantic images in our heads are often not translated to reality.
Software developers spend most of their time on tasks other than building. They attend meetings, discuss specifications, plan, and tidy up existing code. And of course, their favorite activity is fixing bugs.
I’ve yet to meet a developer who loves finding issues in their codebase. But this frustration likely stems from the fact that finding and reproducing errors takes a long time.
Historically, software developers have had to search for the needle in the haystack. They’ve had to find the answers themselves, rather than relying on those screenshots from users posted in a Microsoft Word document.
What browser and version are you using? What OS? Can you tell me exactly where you clicked? Then what happened? What page were you on before? How did you even get to this screen?
So many questions, so few (useful) answers.
Debugging an issue can take forever!
Relying on users to report problems
Many software development teams still rely on users to report problems with their applications.
Which is kinda crazy these days.
It’s just like fast food restaurant chains. They put the onus on customers to clear their own tables by providing trays and trash disposal stations. The restaurant’s food might have been terrible. But the customer could’ve calmly cleared their table, dropped off their trash, and walked away. Unless they take the time to complain, staff assume another happy customer just left the restaurant.
But they’ll never return.
Some developers expect users to fend for themselves when using their applications. After all, if nobody is reporting problems, we don’t have any — right? Putting the onus on your users to report the problems they experience is limiting. You will see around one percent of the total instances affecting your entire user base, and technical details will be thin and inconsistent.
Developers will spend more time trying to debug the problem — using small bits of information — than fixing it. That’s if they can find the problem at all.
Your software isn’t as good as you think it is
I was talking to a friend of mine who works for a large online retailer. He explained to me how they’d found a big problem in their online ordering system that nobody had known about.
After several days of investigation they couldn’t pinpoint the problem. At that point, they decided to try out a dedicated tool to detect and diagnose errors in their application.
What they found was alarming.
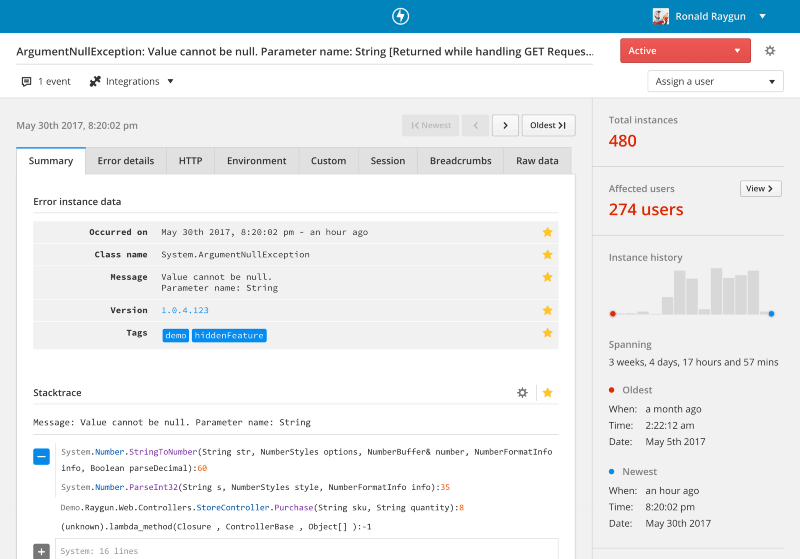
The tool identified that one of the eight servers was running out of memory and throwing errors. This caused the user’s checkout flow to grind to a complete halt.
One in every eight user checkout sessions was broken.
Finding and fixing this issue resulted in an immediate uptick in sales of $20,000 a month! People were no longer running into problems during the purchase process.
They estimated that it had affected over 5,000 users — yet they had only received two support tickets about it.
Although the team was happy to find the issue, there was also a crushing disappointment. An unidentified error had likely resulted in upwards of $100,000 in missed revenue.
Emailing yourself when errors occur is a dumb idea
You can sit watching a live stream of problems happening in your code tailing logs. And you can hire a warm body to do so while you’re asleep. Or, you can email yourself when an unhandled exception occurs — seems like a great idea!
Until you do it.
If you set this up, it might look like this:
public void TryProcessLineNumber(int lineNumber){ try { ProcessLineNumber(lineNumber); } catch (Exception ex) { LetMyselfKnowViaEmail("Something went wrong: " + ex.Message); }}
But beware of the problems it can create.
Emailing errors might be suitable for smaller side projects and personal projects. But once you expand outside of that, things start to get messy. Very, very messy:
- Diagnostic details are limited
- It’s hard to set up notification rules and things start to get noisy
- An exception caught in an infinite loop can send 50,000 emails to your inbox overnight
- Errors have no priority level or impact visibility and all appear equal
- After you reach more than one hundred emails, you give up reading them

Not long after you start emailing yourself errors, you start ignoring them. Or you filter them into a folder because there is just so much noise and no signal.
You’re left to trawl through thousands of emails looking for the right error instance.
We need something smarter.
ELMAH — logging your exceptions
ELMAH (Error Logging Modules and Handlers) is an application-wide error logging facility that is completely pluggable. It can be dynamically added to a running ASP.NET web application, or even all ASP.NET web applications on a machine, without any need for recompilation or redeployment.
ELMAH doesn’t support every programming language and platform. Since its functionality is fairly limited when drilling into the root cause of an issue, it’s usually used for smaller projects. It’s also not really in active development these days, but at least it’s something, and it’s free.
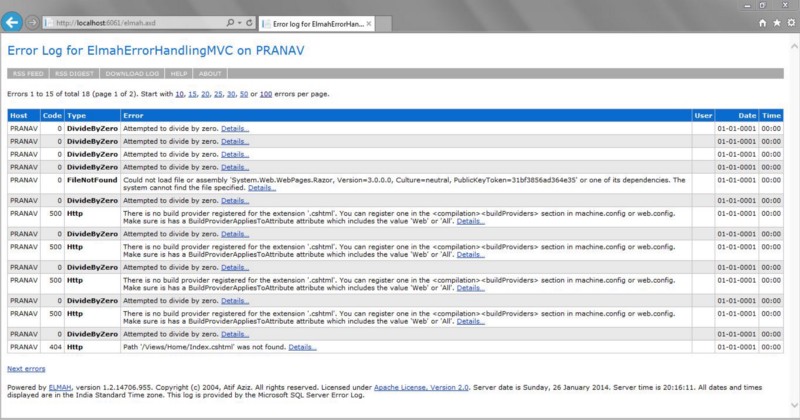
ELMAH is basically a NuGet package for .NET web applications. It logs every exception that occurs on one or more websites to the storage you choose. Unlike other logging frameworks, ELMAH logs into every exception automatically when configured in its simplest form. Sure, there’s an API you can use to log custom errors. But most people only use the automatic part. In this tutorial we will only focus on the basic parts.
Here’s a great tutorial on how to get started.
Dedicated error & crash reporting tools
If you’re serious about handling errors and crashes in your applications, use a dedicated error monitoring tool. It detects and diagnoses problems affecting your users automatically by adding a provider to your application code.
It’s a few lines of code — thats all it takes.
Using a tool like this allows you to:
- Cut out noisy exceptions and focus on the things that matter, like impacting users
- Set up configurable notifications via email, Slack, or HipChat
- Use one tool to track multiple languages and platforms
- Take advantage of error grouping for similar errors
- Keep your whole team on top of errors and their resolution
Tools like these are not cheap or free like the other programs we’ve discussed, but what price do you put on your time? Say you use a free solution. Then you have to stop coding for three hours while you try to reproduce a bug. This is actually a very poor return on investment.
Teams who are looking to move quickly and deliver new functionality to users would say that such professional solutions are worth every cent. They can cut the time developers spend fixing bugs and get them back to coding and building improvements.
Even if you think your code is perfect, and users are not having any issues, plug in a tool like Raygun. You’ll be surprised at what you find.
Take a proactive approach and reap the rewards
We’d all love for technology to fix our software issues automatically. Unfortunately, I think we’re a while away from self-healing and self-aware software.
You can also plug error monitoring solutions into developer workflows to make error and crash resolution easier. But data is often soiled and segregated from context in other systems.
The future of error monitoring lies in making sure all teams — front end, back end, management or support — have complete visibility on every problem their users encounter. And then have the ability to solve it right away.
This also extends to upcoming trends in the continuous delivery and deployment space. You can apply fixes and ship to production within minutes of identifying the problem. You don’t have to wait weeks before the next major deployment.
Put the focus on your team when handling errors and crashes in your own applications. Discover problems before your users do, and don’t rely on them to report errors.
Because they won’t.