
By Slobodan Stojanovic
Yes, you read that right: this article is about running Google Chrome (the browser) in AWS Lambda (the serverless computing platform). Why would anyone run a browser on the server[less] side? Is this some web version of “Will It Blend?”
As much as I would love to see (or do) a serverless “Will It Blend?” series that runs weird things in AWS Lambda, this is not it.
But what is this article, then? Ok, it’s story time!
Once upon a time at Cloud Horizon we worked with a client that had some weird SVGs that needed to be converted to PNGs. None of the SVG-to-PNG tools were working, because the SVGs contained <foreignObject> elements.
This problem could’ve been solved in many different ways. The optimal solution would’ve been to analyze why they had HTML elements embedded in SVG files. But, as is often case in real-world projects, the reason was hidden behind a pile of legacy code and legacy decisions. And, of course, a solution was required ASAP.
The quest for the perfect solution became the quest for the fastest decent solution in the given circumstances.
The foreign objects in the SVGs were HTML elements, and the best tool for showing HTML elements is a browser. But how could we use the browser to solve this issue?
Manually, we would open an SVG in the browser and take a screenshot. We should’ve be able to do the same with PhantomJS, a headless WebKit scriptable with a JavaScript API. We tried, but it didn’t work, because of the lack of support for SVG foreign objects in PhantomJS.
What else could we use? Imagine using Chrome the way we would use PhantomJS. Wait! We might be able do it. Someone from the team had read about headless Chrome recently. That sounded like a perfect tool for our weird problem. We tried to use headless Chrome and it worked!
Solve the problem without hurting your future self
Finally, we had a viable solution. But, we needed to figure out how to integrate this solution into client’s application without adding an extra layer of future legacy code.
Our client used AWS, and SVGs files were in the Amazon S3 bucket. That gave us the opportunity to use serverless for the SVG to PNG converter.
Serverless solutions are cheap, and for this kind of converter it was free, so we didn’t need permission to use it. That, and the fact that the infrastructure didn’t need any setup, allowed us to move fast. Another big win was an isolation, which allowed us to work without understanding the legacy code. Also, our serverless converter would be easy to remove in the future.
A quick note: Serverless is a method of deploying and running applications on cloud infrastructure, on a pay-per-use basis, and without renting or buying servers. To learn more about serverless and how it works with AWS, see the free first chapter of our new book “Serverless Applications with Node.js” here.
As shown in the diagram below, our plan was the following:
- Client uploads SVGs to S3 bucket as they did before.
- S3 triggers an AWS Lambda function.
- Inside Lambda function, Node.js downloads SVG from S3 bucket and starts the headless Chrome.
- Headless Chrome loads SVG and takes the screenshot.
- Node.js app then uploads screenshot PNG image back to S3 bucket.
- Client uses PNG image from the S3 bucket.
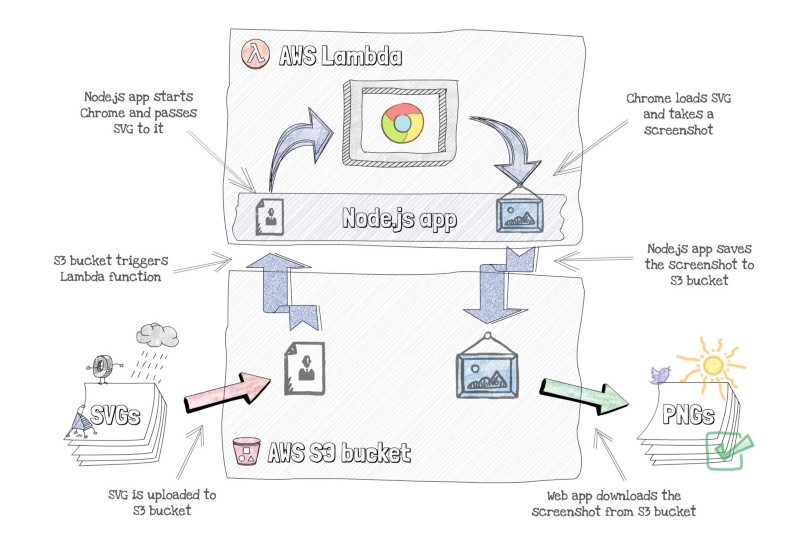 Serverless screenshots app flow
Serverless screenshots app flow
Show me the code
We decided to use Node.js, so the first step was to check if Google Chrome for AWS Lambda existed in NPM. We were not disappointed: a package called serverless chrome had us covered.
Note: AWS Lambda runs on Amazon Linux. To run a third-party library, such as Google Chrome, you need to compile it as a static binary using Amazon Linux. To learn more about that process, check out how to compile and run Pandoc on AWS Lambda here.
Another missing piece was a way to interact with Google Chrome in AWS Lambda. The most popular library, Puppeteer, seemed quite big for the task, so we used chrome-remote-interface.
Let’s rebuild the project together. But, before doing that, there are two prerequisites:
- You’ll need to have Node.js with npm installed.
- You’ll need to have an AWS account and setup the credentials (see how to do that here).
To install both dependencies, you should initiate a new Node.js project and run the following command in your terminal:
npm install @serverless-chrome/lambda chrome-remote-interface --save
This Lambda function is not big, and you can fit it in one file and less than 100 lines of code. But, to make our function testable, we’ll use the structure shown in the figure below.
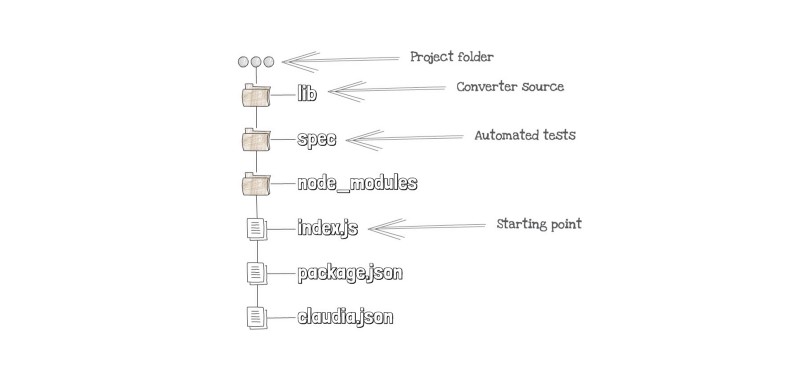 Project folder structure
Project folder structure
How do you test serverless functions? The concept is similar to any other Node.js app: you should apply a hexagonal architecture, and then you can use your favorite Node.js tool for testing. Our choice is Jasmine. If you want to learn more about testing serverless apps, you can take a look at testing chapter of our book here.
In our structure, the index.js file is just handling the event, passing it to the converter function, and responding back. This file should look like this code snippet:
Again, for testing purposes, the converter logic is in the following files:
convert.js: a main file that wires all other files.download-from-s3.js: a function that downloads SVG from S3 bucket.save-svg-and-get-dimensions.js: a function that saves SVG the file to the/tmpfolder and reads its dimensions.screenshot-with-headless-chrome.js: a function that loads file in headless Chrome and takes the screenshot.upload-to-s3.js: a function that uploads a screenshot (PNG file) back to S3.
Most of the files are simple, with just a few lines of code. But to keep this article short, let’s see the most important ones: convert.js and screenshot-with-headless-chrome.js.
As you can see in the next code snippet, the convert function is doing the following:
- Downloading the SVG file from S3, using the function from the
download-from-s3.jsfile. - Preparing the path for SVG file in
/tmpfolder, and invoking the function to save SVG file and get its default dimensions. - Opening local SVG file in headless Chrome and taking a screenshot using the function from
screenshot-with-headless-chrome.jsfile. - Upload screenshot to S3 bucket using the function from
upload-to-s3.jsfile.
Running headless Chrome
The last important piece of this puzzle is running headless Chrome. To do so, we’ll launch Chrome using the @serverless-chrome/lambda module, and than interact with it using the chrome-remote-interface module.
The Chrome remote interface gets the list of all tabs, and connects to the first one. Then it enables Page and Network for the client.
When Page and Network are ready, Chrome remote interface navigates to the URL you provided (local file:// path to the SVG file), waits for it to be loaded, and takes the screenshot.
The code of the screenshot-with-headless-chrome.js file should look like the following code snippet:
Now that the code is ready, it’s time to deploy it to AWS Lambda. But because Google Chrome is bigger than the 50mb limit on AWS Lambda, deployment is not as smooth as you would expect.
How can we squeeze the elephant into the car trunk?
With serverless apps, you often end up with more code for automating deployment than for the business logic of your app. That’s a sign that the risk has shifted to deployment. And therefore, the deployment process should be well tested and something you can trust.
To avoid unexpected hiccups, we use Claudia.js fort the deployment of serverless Node.js apps to AWS Lambda and API Gateway.
With Claudia.js, we would normally just do claudia create --region eu-central-1 --handler index.handler. But in the case of headless Chrome, this command fails because of the size of the package you are trying to deploy.
AWS Lambda has a 50MB limit on deployment package size for compressed files. Fortunately, there is also 250MB limit for uncompressed code, which you can use via S3 bucket. NThe code is uploaded to S3 bucket and then transferred to the AWS Lambda function uncompressed from there.
 How can we squeeze the “elephant” into the car trunk?
How can we squeeze the “elephant” into the car trunk?
To do so with Claudia, run the following command:
claudia create --region eu-central-1 --handler index.handler --memory 1024 --timeout 60 --use-s3-bucket S3_BUCKET_NAME
Important notes for the previous command:
- Replace
S3_BUCKET_NAMEwith the name of an S3 bucket you own. You can create a new one and use it just as a deployment helper. - Pick any region you are closest to, just make sure your Lambda function is in the same region as helper S3 bucket. See all supported regions here.
- If your main file is named differently, you’ll need to update handler in the command to the name of the file with
.handlerinstead of.jsextension. For example, if the file name ismain.js, your handler would bemain.handler. - Increase the default memory a bit, because event a headless Chrome needs more than the default 128MB.
- Increase the timeout (a few seconds should be enough). But as you don’t pay for the timeout, and rather just the actual execution time, you can put a bit more, even around 5 minutes (max).
A few moments later (depending on your internet speed), you should see the confirmation that everything has been deployed successfully.
Note: In case you want to update your code, run the claudia update --use-s3-bucket S3_BUCKET_NAME command. To learn how to use Claudia.js, check out the tutorial section on the website.
The last step before the test ride is to set the S3 trigger for your Lambda function. Claudia has you covered for that one too. Just run the following command from your terminal:
claudia add-s3-event-source --bucket S3_BUCKET --suffix svg
Again, replace S3_BUCKET with the name of the S3 bucket which will be used for the SVG and PNG files. By default, PNG will be saved to the same folder where the SVG file is located.
And when the command runs successfully, that’s it. Your serverless file converter is ready.
Test ride
It’s time for a test ride!
So how do you test a serverless converter? Simply by uploading an SVG file to your S3 bucket. And what then? Refresh the bucket a few seconds later and you’ll see a PNG file with the same name. You’ll be surprised how fast it actually works! Headless Chrome seems to be faster than the Chrome browser on my machine. Maybe I should browse the web in headless mode from now on. ?
Wrapping up
So, that’s how we solved the problem our client had without hurting our future selves. It’s not the best solution, but it was the best solution we were able to come up in a short timeframe and given the circumstances.
But what’s the point of this story? Why should you care about running Chrome in AWS Lambda if you don’t have a similar client?
There are many potential use cases. If you remember the testing pyramid, UI tests are slow and expensive. But what if you can run a few hundreds or even thousands of them in parallel and pay only for execution time? There are some UI testing tools that are already working on a similar integration, such as Appraise.

I hope you enjoyed the story. Expect more to come soon!
As always, many thanks to my friends Aleksandar Simović for help and feeback on the article.
All illustrations are created using SimpleDiagrams4 app.
No cows were harmed in the making of this article.
If you want to learn more about building and testing serverless apps using Node.js and AWS, check out “Serverless Applications with Node.js”, the book I wrote with Aleksandar Simovic for Manning Publications:
Serverless Applications with Node.js
_A compelling introduction to serverless deployments using Claudia.js._www.manning.com
The book will teach you more about serverless apps, with code examples. You’ll learn how to build and debug a real world serverless API (with DB and authentication) using Node and Claudia.js. And you’ll learn how to build chatbots, for Facebook Messenger and SMS (using Twilio), and Alexa skills.