
Correlations are a great tool for learning about how one thing changes with another. After reading this, you should understand what correlation is, how to think about correlations in your own work, and code up a minimal implementation to calculate correlations.
A correlation is about how two things change with each other
Correlation is an abstract math concept, but you probably already have an idea about what it means. Here are some examples of the three general categories of correlation.
As you eat more food, you will probably end up feeling more full. This is a case of when two things are changing together in the same way. One goes up (eating more food), then the other also goes up (feeling full). This is a positive correlation.
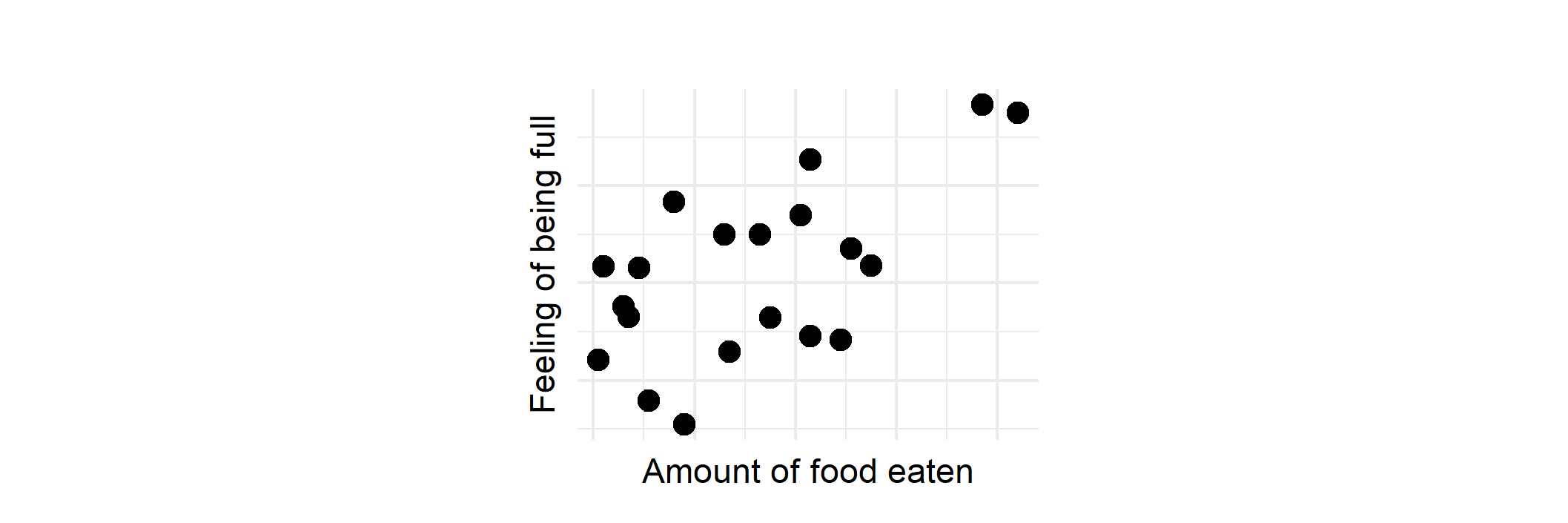
Positive correlation between food eaten and feeling full. More food is eaten, the more full you might feel (trend to the top right). R code
When you're in a car and it goes faster, you will probably get to your destination faster and your total travel time will be less. This is a case of two things changing in the opposite direction (more speed, but less time). This is a negative correlation.

Negative correlation between car speed and travel time. The faster the car, less travel time (trend to the bottom right). R code
There is also a third possible way two things can "change". Or rather, not change. For example, if you were to gain weight and looked at how your test scores changed, there probably won't be any general pattern of change in your test scores. This means there's no correlation.

An exaggerated plot of no correlation between weight gain and test scores. R code
Knowing about how two things change together is the first step to prediction
Being able to describe what is going on in our previous examples is great and all. But what's the point? The reason is to apply this knowledge in a meaningful way to help predict what will happen next.
In our eating example, we may record how much we eat for a whole week and then make a note of how full we feel afterwards. As we found before, the more we eat, the more full we feel.
After collecting all of this information, we can ask more questions about why this happens to better understand this relationship. Here, we may start to ask what kind of foods make us more full, or whether the time of day affects how full we feel as well.
Similar thinking can be applied to your job or business as well. If you notice sales or other important metrics are going up or down with other measure of your business (in other words, things are positively correlated or negatively correlated), it may be worth exploring and learning more about that relationship to improve your business.
Correlations can have different levels of strength
We've covered some general correlations as either
positive,
negative, or
non-existent
Although those descriptions are okay, all positive and negative correlations are not all the same.
These descriptions can also be translated to numbers. A correlation value can take on any decimal value between negative one, (-1), and positive one, (+1).
Decimal values between (-1) and (0) are negative correlations, like (-0.32).
Decimal values between (0) and (+1) are positive correlations, like (+0.63).
A perfect zero correlation means there is no correlation.
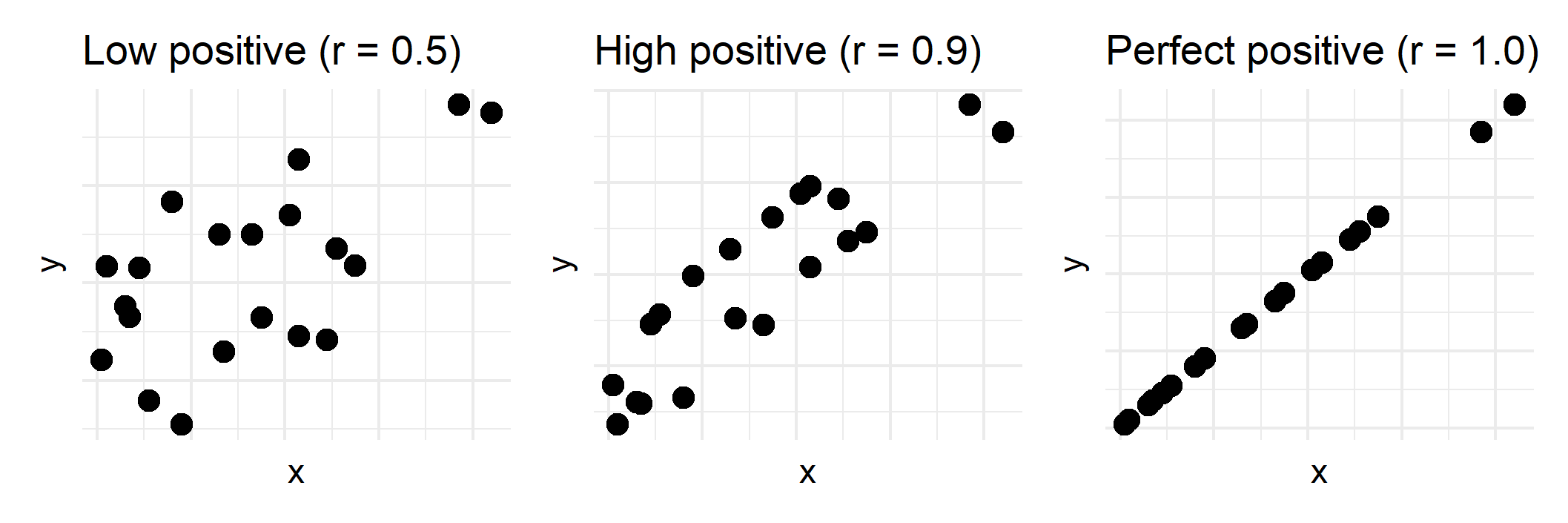
For each type of correlation, there is a range of strong correlations and weak correlations. Correlation values closer to zero are weaker correlations, while values closer to positive or negative one are stronger correlation.
Strong correlations show more obvious trends in the data, while weak ones look messier. For example, the stronger high, positive correlation below looks more like a line compared to the weaker and lower, positive correlation.

Varying levels of positive correlations. R code.
Similarly, strongly negative correlations have a more obvious trend than the weaker and lower negative correlation.

Varying levels of negative correlations. R code
Where does the r value come from? And what values can it take?
The "r value" is a common way to indicate a correlation value. More specifically, it refers to the (sample) Pearson correlation, or Pearson's r. The "sample" note is to emphasize that you can only claim the correlation for the data you have, and you must be cautious in making larger claims beyond your data.
The table below summarizes what we've covered about correlations so far.
| Pearson's r value | Correlation between two things is... | Example |
| r = -1 | Perfectly negative | Hour of the day and number of hours left in the day |
| r < 0 | Negative | Faster car speeds and lower travel time |
| r = 0 | Independent or uncorrelated | Weight gain and test scores |
| r > 0 | Positive | More food eaten and feeling more full |
| r = 1 | Perfectly positive | Increase in my age and increase in your age |
In the next few sections, we will
Break down the math equation to calculate correlations
Use example numbers to use this correlation equation
Code up the math equation in Python and JavaScript
Breaking down the math to calculate correlations
As a reminder, correlations can only be between (-1) and (1). Why is that?
The quick answer is that we adjust the amount of change in both variables to a common scale. In more technical terms, we normalize how much the two variables change together by how much each of the two variables change by themselves.
From Wikipedia, we can grab the math definition of the Pearson correlation coefficient. It looks very complicated, but let's break it down together.
$$\textcolor{lime}{r} { \textcolor{#4466ff}{x} \textcolor{fuchsia}{y} } = \frac{ \sum{i=1}^{n} (x_i - \textcolor{green}{\bar{x}})(y_i - \textcolor{olive}{\bar{y}}) }{ \sqrt{ \sum_{i=1}^{n} (x_i - \textcolor{green}{\bar{x}})^2 \sum_{i=1}^{n} (y_i - \textcolor{olive}{\bar{y}})^2 } }$$
From this equation, to find the (\textcolor{lime}{\text{correlation}}) between an ( \textcolor{#4466ff}{\text{x variable}} ) and a ( \textcolor{fuchsia}{\text{y variable}} ), we first need to calculate the ( \textcolor{green}{\text{average value for all the } x \text{ values}} ) and the ( \textcolor{olive}{ \text{average value for all the } y \text{ values}} ).
Let's focus on the top of the equation, also known as the numerator. For each of the ( x) and (y) variables, we'll then need to find the distance of the (x) values from the average of (x), and do the same subtraction with (y).
Intuitively, comparing all these values to the average gives us a target point to see how much change there is in one of the variables.
This is seen in the math form, (\textcolor{#800080}{\sum_{i=1}^{n}}(\textcolor{#000080}{x_i - \overline{x}})), (\textcolor{#800080}{\text{adds up all}}) the (\textcolor{#000080}{\text{differences between}}) your values with the average value for your (x) variable.
In the bottom of the equation, also known as the denominator, we do a similar calculation. However, before we add up all of the distances from our values and their averages, we will multiple them by themselves (that's what the ((\ldots)^2) is doing).
This denominator is what "adjusts" the correlation so that the values are between (-1) and (1).
Using numbers in our equation to make it real
To demonstrate the math, let's find the correlation between the ages of you and your siblings last year ([1, 2, 6]) and your ages for this year ([2, 3, 7]). Note that this is a small example. Typically you would want many more than three samples to have more confidence in your correlation being true.
Looking at the numbers, they appear to increase the same. You may also notice they are the same sequence of numbers but the second set of numbers has one added to it. This is as close to a perfect correlation as we'll get. In other words, we should get an (r = 1).
First we need to calculate the averages of each. The average of ([1, 2, 6]) is ((1+2+6)/3 = 3) and the average of ([2, 3, 7]) is ((2+3+7)/3 = 4). Filling in our equation, we get
$$r { x y } = \frac{ \sum{i=1}^{n} (x_i - 3)(y_i - 4) }{ \sqrt{ \sum_{i=1}^{n} (x_i - 3)^2 \sum_{i=1}^{n} (y_i - 4)^2 } }$$
Looking at the top of the equation, we need to find the paired differences of (x) and (y). Remember, the (\sum) is the symbol for adding. The top then just becomes
$$(1-3)(2-4) + (2-3)(3-4) + (6-3)(7-4)$$
$$= (-2)(-2) + (-1)(-1) + (3)(3)$$
$$= 4 + 1 + 9 = 14$$
So the top becomes 14.
$$r { x y } = \frac{ 14 }{ \sqrt{ \sum{i=1}^{n} (x_i - 3)^2 \sum_{i=1}^{n} (y_i - 4)^2 } }$$
In the bottom of the equation, we need to do some very similar calculations, except focusing on just the (x) and (x) separately before multiplying.
Let's focus on just ( \sum_{i=1}^n (x_i - 3)^2 ) first. Remember, (3) here is the average of all the (x) values. This number will change depending on your particular data.
$$(1-3)^2 + (2-3)^2 + (6-3)^2$$
$$= (-2)^2 + (-1)^2 + (3)^2 = 4 + 1 + 9 = 14$$
And now for the (y) values.
$$(2-4)^2 + (3-4)^2 + (7-4)^2$$
$$(-2)^2 + (-1)^2 + (3)^2 = 4 + 1 + 9 = 14$$
We those numbers filled out, we can put them back in our equation and solve for our correlation.
$$r _{ x y } = \frac{ 14 }{ \sqrt{ 14 \times 14 }} = \frac{14}{\sqrt{ 14^2}} = \frac{14}{14} = 1$$
We've successfully confirmed that we get (r = 1).
Although this was a simple example, it is always best to use simple examples for demonstration purposes. It shows our equation does indeed work, which will be important when coding it up in the next section.
Python and JavaScript code for the Pearson correlation coefficient
Math can sometimes be too abstract, so let's code this up for you to experiment with. As a reminder, here is the equation we are going to code up.
$$r { x y } = \frac{ \sum{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y}) }{ \sqrt{ \sum_{i=1}^{n} (x_i - \bar{x})^2 \sum_{i=1}^{n} (y_i - \bar{y})^2 } }$$
After going through the math above and reading the code below, it should be a bit clearer on how everything works together.
Below is the Python version of the Pearson correlation.
import math
def pearson(x, y):
"""
Calculate Pearson correlation coefficent of arrays of equal length.
Numerator is sum of the multiplication of (x - x_avg) and (y - y_avg).
Denominator is the squart root of the product between the sum of
(x - x_avg)^2 and the sum of (y - y_avg)^2.
"""
n = len(x)
idx = range(n)
# Averages
avg_x = sum(x) / n
avg_y = sum(y) / n
numerator = sum([(x[i] - avg_x)*(y[i] - avg_y) for i in idx])
denom_x = sum([(x[i] - avg_x)**2 for i in idx])
denom_y = sum([(y[i] - avg_y)**2 for i in idx])
denominator = math.sqrt(denom_x * denom_y)
return numerator / denominator
Here's an example of our Python code at work, and we can double check our work using a Pearson correlation function from the SciPy package.
import numpy as np
import scipy.stats
# Create fake data
x = np.arange(5, 15) # array([ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
y = np.array([24, 0, 58, 26, 82, 89, 90, 90, 36, 56])
# Use a package to calculate Pearson's r
# Note: the p variable below is the p-value for the Pearson's r. This tests
# how far away our correlation is from zero and has a trend.
r, p = scipy.stats.pearsonr(x, y)
r # 0.506862548805646
# Use our own function
pearson(x, y) # 0.506862548805646
Below is the JavaScript version of the Pearson correlation.
function pearson(x, y) {
let n = x.length;
let idx = Array.from({length: n}, (x, i) => i);
// Averages
let avgX = x.reduce((a,b) => a + b) / n;
let avgY = y.reduce((a,b) => a + b) / n;
let numMult = idx.map(i => (x[i] - avg_x)*(y[i] - avg_y));
let numerator = numMult.reduce((a, b) => a + b);
let denomX = idx.map(i => Math.pow((x[i] - avgX), 2)).reduce((a, b) => a + b);
let denomY = idx.map(i => Math.pow((y[i] - avgY), 2)).reduce((a, b) => a + b);
let denominator = Math.sqrt(denomX * denomY);
return numerator / denominator;
};
Here's an example of our JavaScript code at work to double check our work.
x = Array.from({length: 10}, (x, i) => i + 5)
// Array(10) [ 5, 6, 7, 8, 9, 10, 11, 12, 13, 14 ]
y = [24, 0, 58, 26, 82, 89, 90, 90, 36, 56]
pearson(x, y)
// 0.506862548805646
Feel free to translate the formula into either Python or JavaScript to better understand how it works.
In conclusion
Correlations are a helpful and accessible tool to better understand the relationship between any two numerical measures. It can be thought of as a start for predictive problems or just better understanding your business.
Correlation values, most commonly used as Pearson's r, range from (-1) to (+1) and can be categorized into negative correlation ((-1 \lt r \lt 0)), positive ((0 \lt r \lt 1)), and no correlation ((r = 0)).
A glimpse into the larger world of correlations
There is more than one way to calculate a correlation. Here we have touched on the case where both variables change at the same way. There are other cases where one variable may change at a different rate, but still have a clear relationship. This gives rise to what's called, non-linear relationships.
Note, correlation does not imply causation. If you need quick examples of why, look no further.
Below is a list of other articles I came across that helped me better understand the correlation coefficient.
If you want to explore a great interactive visualization on correlation, take a look at this simple and fantastic site.
Using Python, there multiple ways to implement a correlation and there are multiple types of correlation. This excellent tutorial shows great examples of Python code to experiment with yourself.
A blog post by Sabatian Sauer goes over correlations using "average deviation rectangles", where each point creates a visual rectangle from each point using the mean, and illustrating it using the R programming language.
And for the deeply curious people out there, take a look at this paper showing 13 ways to look at the correlation coefficient (PDF).
Follow me on Twitter and check out my personal blog where I share some other insights and helpful resources for programming, statistics, and machine learning.
Thanks for reading!