

原文: How to Create and Manipulate SQL Databases with Python
Python と SQL という 2 つの言語は、データアナリストにとって最も重要なものです。
この記事では、Python と SQL を結びつけるために知る必要があることについてすべてお伝えします。
リレーショナルデータベースから、機械学習パイプラインに直接データを取得したり、独自のデータベースの中に Python アプリケーションからデータを保存したり、あるいはあなたが思いつきそうな、他のあらゆるユースケースについて学習します。
一緒に学ぶ項目を以下に挙げます:
- なぜ Python と SQL を一緒に使用する方法を学ぶのか?
- Python の開発環境と MySQL サーバーの設定方法
- Python で MySQL サーバーに接続する
- 新しいデータベースを作成する
- テーブルとリレーションシップを作成する
- テーブルにデータを追加する
- データの読み取り
- レコードを更新する
- レコードを削除する
- Python のリストからレコードを作成する
- 以上のことを将来にわたって実行できる、再利用可能な関数を作成する
非常に役に立つ素晴らしい内容がたくさんあります。さあ学習に入りましょう!
事前のお知らせ: このチュートリアルの中で使用されるすべてのコードを含む Jupyter Notebook のファイルを、 こちらの GitHub リポジトリで入手できます。その内容に沿ってコーディングすることを強く推奨します!
このチュートリアルで使用されているデータベースと SQL コードは、以前に私が Towards Data Science 上で投稿した、Introduction to SQL (SQL 入門) という一連の記事からすべて引用しています。(記事を閲覧できない場合は、こちらから私 (原著者) に連絡していただければ、無料で閲覧できるリンクを送ることができます) 。
SQL とリレーショナルデータベースの背後にある概念について、あまりよく知らない場合は、前述の一連の記事をお勧めします。(もちろん、freeCodeCamp にも優れた資料がたくさんあります!)
なぜ Python と SQL を一緒に使用するのか?
データアナリストとデータサイエンティストにとって、Python には有利な点が多くあります。膨大なオープンソースライブラリによって、Python はデータアナリストにとって非常に便利なツールになっています。
データ解析向けの pandas、NumPy、Vaex や、データビジュアリゼーション (データ可視化) 向けの Matplotlib、seaborn、Bokeh、そして機械学習アプリケーション向けの TensorFlow、scikit-learn、PyTorch などがあります (まだまだたくさんあります) 。
その (比較的) やさしい学習曲線と用途の広さを思えば、Python が世界で最も急成長しているプログラミング言語のひとつであることも納得がいきます。
ではデータ解析に Python を用いるとして、次の質問をする価値があります - すべてのデータはどこからやってくるのでしょうか?
データセットには多種多様なソースがある一方で、多くの場合 - 特に企業活動のなかでは - データはリレーショナルデータベースの中に保存されています。
リレーショナルデータベースはきわめて効率的でパワフルであり、あらゆる種類のデータの create - 生成、 read - 読み取り、update - 更新、delete - 削除に広く使用されています。
最も広く使用されているリレーショナルデータベース管理システム (RDBMS) - Oracle、MySQL、Microsoft SQL Server、PostgreSQL、IBM DB2 - のすべては、Structured Query Language (構造化問い合わせ言語 - SQL) を使用して、データを取得し変更します。
各 RDBMS が、わずかに異なる SQL 風の言語を使用していることに注意してください。大抵の場合、ある RDBMS 向けに記述された SQL コードは、別の RDBMS 内では (通常はごくわずかな) 変更を加えない限り動作しません。しかし、概念、構造、操作はほとんど同じです。
これはつまり、RDBMS を扱っているデータアナリストにとって、SQL をしっかり理解していることが極めて重要であるということを意味します。Python と SQL を一緒に使用する方法を知っていると、データを扱う際にさらに有利です。
ここからは、その方法について詳しくお伝えします。
はじめに
事前に必要なものとそのインストール
このチュートリアルの内容に沿ってコーディングするためには、Python の開発環境を独自に設定する必要があります。
私は Anaconda を使用していますが、他にも多くの方法があります。さらにサポートが必要な場合は、「Pythonをインストールする方法」と google で検索してください。また、このチュートリアル用の Jupyter Notebook に沿ってコーディングする場合には、Binder が使用できます。
この記事では、無料であり業界内で広く用いられている、MySQL Community Server を使用します。Windows を使用しているならば、設定の際にこちらのガイドが役に立ちます。Mac と Linux ユーザー向けのガイドもあります。(ただし、linux のディストリビューションによって、設定方法が異なるかもしれません)。
以上の設定が済んだら、それらを相互につなげる必要があります。
そのためには、Python のライブラリである MySQL Connector をインストールしなければなりません。こちらの案内に従ってインストールするか、次の pip コマンドを使用してください:
pip install mysql-connector-python
また、pandas を使用するので、必ず同じようにインストールしておいてください。
pip install pandas
ライブラリのインポート
Python のあらゆるプロジェクトと同じで、まず最初にしたいことはライブラリのインポートです。
プロジェクトの最初に、使用するすべてのライブラリをインポートすることをお勧めします。そうすれば、コードを読んだりレビューする人が、何が起こるのかを大まかに知ることができるので、不意を打つようなことがなくなります。
このチュートリアルでは、MySQL Connector と pandas の 2 つのライブラリだけを使用します。
import mysql.connector
from mysql.connector import Error
import pandas as pd
Error 関数を個別にインポートしているので、それを自分で記述する関数のために簡単に利用できます。
MySQL サーバーに接続する
この時点で、自分のシステム上に MySQL Community Server が設定されていなければなりません。その次に、このサーバーへの接続を確立できる以下のコードを、Python で記述する必要があります。
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connection
再利用できる関数を、このようなコードで作成するのをお勧めします。そうすれば、その関数を何度も楽に使用できます。一度コードを記述してしまえば、それを今後のあらゆるプロジェクトでも再利用できるので、未来の自分も快適になります!
上記のコードで何が行われているのかを理解するために、行単位で見直していきましょう:
最初の行は関数名 (create_server_connection) と、関数が取る引数名 (host_name、user_name、および user_password) を定義しています。
多数の接続が開くことによってサーバーが混雑しないように、次の行で既存の接続を閉じます。
その次に、Python の try-except ブロックを使用して、起こり得るエラーを処理しています。はじめの部分は引数内でユーザーが指定する詳細情報を用いた mysql.connector.connect() メソッドを使用して、サーバーへの接続を試しています。接続に成功すると、関数がちょっとした成功メッセージを出力に表示してくれます。
ブロックの except の部分は、エラーが発生してしまうという残念な状況において、MySQL サーバーが返すエラーを出力に表示します。
最後に、もし接続に成功していれば、関数は connection オブジェクトを返します。
実務ではよく、関数の出力を変数に代入して使います。これが connection オブジェクトとなります。その後で、(cursor などの) 他のメソッドを connection オブジェクトに適用することで、別の便利なオブジェクトを作成できます。
connection = create_server_connection("localhost", "root", pw)
これは次の成功メッセージを出力するはずです:

新しいデータベースを作成する
接続を確立したので、次のステップではサーバー上に新しいデータベースを作成します。
このチュートリアルではこれを 1 度しか行いませんが、将来のプロジェクトで再利用できる、便利で優れた関数を手に入れるために、関数をもう 1 つ記述します。
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")
この関数は connection (connection オブジェクト) と query (次のステップで記述する SQL クエリ) の 2 つの引数を取ります。そして、接続を介してサーバー内でクエリを実行します。
connection オブジェクトに cursor メソッドを適用して、cursor オブジェクトを作成します (MySQL Connector はオブジェクト指向プログラミングパラダイムを使用しているので、親オブジェクトから特性を継承しているオブジェクトが多く存在します) 。
この cursor オブジェクトは、execute、executemany (このチュートリアル内でこれらを使用します) などのメソッドの他に、いくつかの便利なメソッドをもちます。
cursor オブジェクトが、MySQL サーバーのターミナルウィンドウ内で点滅しているカーソルへのアクセスを提供するものであると考えると、わかりやすいかもしれません。
次に、データベースを作成するクエリを定義して関数を呼び出します:

このチュートリアルで使用するすべての SQL クエリは、私の Introduction to SQL tutorial series (SQL 入門チュートリアルシリーズ) の中で解説されており、すべてのコードは、こちらの GitHub リポジトリ内の関連する Jupyter Notebook の中で見つけることができるので、このチュートリアル内の SQL コードが、何を行うのかについての説明はいたしません。
とはいえ、これはおそらく考えられる最もシンプルな SQL クエリです。英語が読めるならば、何を行っているかはほぼ理解できます!
create_database 関数を、上記の引数を指定して実行することで、「school」という名前のデータベースがサーバー内に作成されます。
なぜこのデータベースは「school」と呼ばれるのでしょうか?このチュートリアル内で、本当は何を実装しようとしているのかについてより詳しく見るのに、今がちょうどいいタイミングかもしれません。
データベースについて
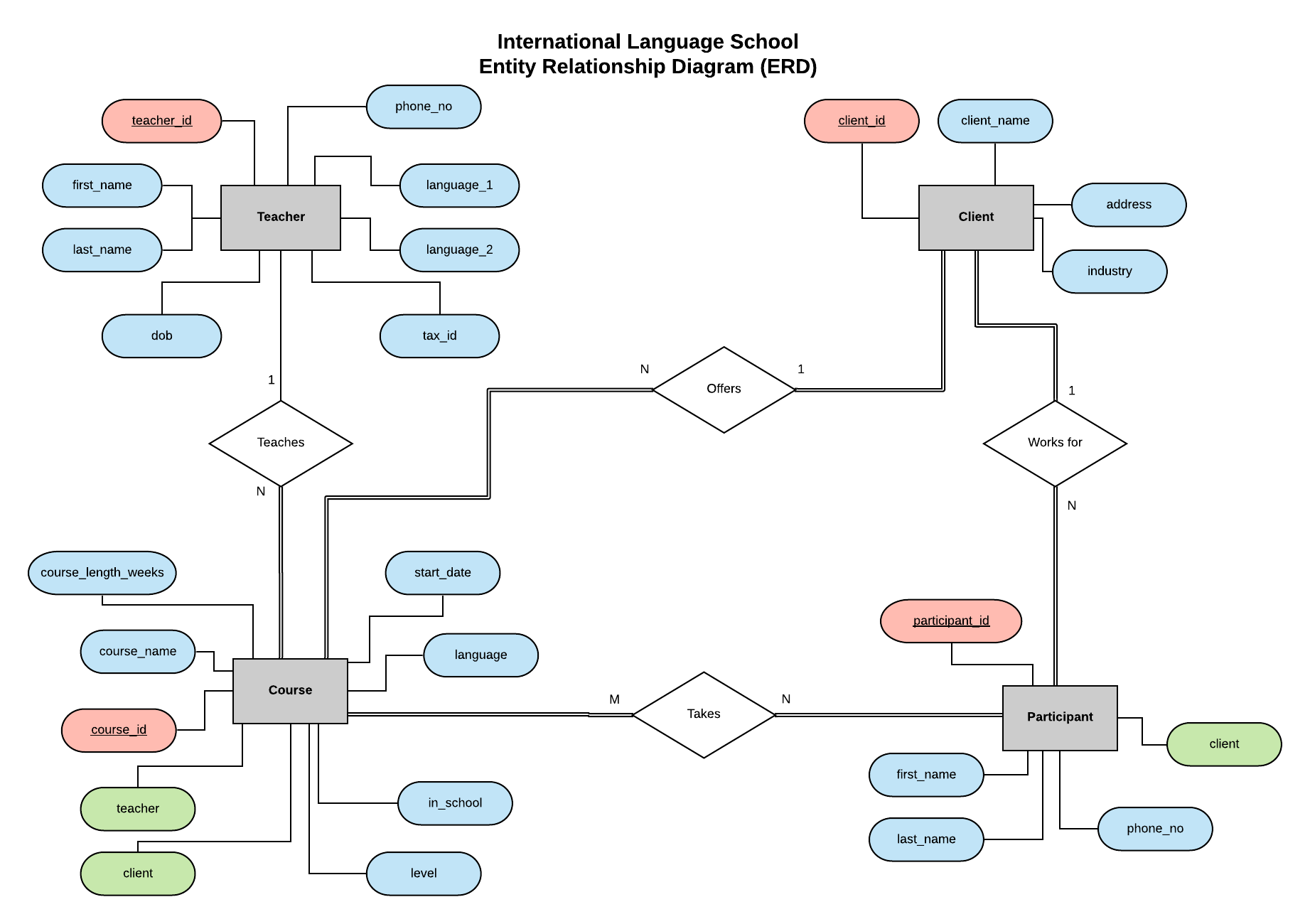
先ほどご紹介したシリーズの中の例にならって、International Language School (国際語学校、ILS) - 法人顧客に専門的な語学レッスンを提供する架空の言語訓練校 - のためのデータベースを実装してみましょう。
この実体関連図 (Entity Relationship Diagram - ERD) は実体 (Teacher - 講師、Client - 法人顧客、Course - 講座、 Participant - 受講者) を配置し、それらの関係を定義します。
ERD とは何か、そしてそれを作成したり、データベースを設計したりする際に、何を考慮すべきなのかについてのすべての情報を、この記事の中で見つけることができます。
SQL のソースコード、データベース要件、およびデータベースに入るデータは、すべてこちらの GitHub リポジトリに含まれていますが、このチュートリアルを進めていくことでも、そのすべてを確認できます。
データベースに接続する
MySQL サーバー内にデータベースを作成したので、create_server_connection 関数を変更してこのデータベースに直接接続できるようにします。
1 つの MySQL サーバー上に複数のデータベースが存在する可能性がある (実際にはそれが一般的ですが) ことに注意し、私たちは常に、また自動的に、自らが関与するデータベースへ接続する必要があります。
データベースへの接続は次のようにして行うことができます:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connection
この関数は、引数 (データベースの名前) をもう 1 つ多く取って、それを connect() メソッドへ引数として渡していること以外は、create_server_connection 関数と全く同じものです。
クエリ実行関数を作成する
ここで (ひとまず) 最後に作ろうとしている関数は、クエリ実行関数という極めて重要なものです。これは、文字列として Python 内に保存されている SQL クエリを取り、それを cursor.execute() メソッドに渡して、サーバー上で実行します。
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")
この関数は、connection.commit() メソッドを使用して、SQL クエリで詳細に記述されているコマンドが実行されているか確認していることを除けば、前の create_database 関数と全く同じです。
これが主力の関数になります。この関数を (create_db_connection と一緒に) 使用することで、テーブルを作成し、テーブル間の関係を設定し、データをテーブルに追加し、データベース内のレコードを更新または削除します。
SQL の専門家であれば、この関数を使用して、すべての複雑なコマンドとクエリを、Python のスクリプトから直接実行できるでしょう。これはデータを管理するためのとても強力なツールになってくれます。
テーブルを作成する
これで、サーバー内での SQL コマンドの実行と、データベースの構築を始める準備がすべて整いました。最初に行うことは、必要なテーブルの作成です。
では講師 (Teacher) のテーブルから始めましょう:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # データベースに接続
execute_query(connection, create_teacher_table) # 定義したクエリを実行
まず最初に、適切な名前の変数へ SQL コマンド (こちらで詳しく解説されています) を代入します。
この場合、Python の複数行にわたる文字列に対する三連引用符表記を使用して、SQL クエリを保存してから、それを execute_query 関数へ渡して実行しています。
この複数行のフォーマットは、純粋に人間がコードを読むためのものであることに注意してください。 もし SQL コマンドがこのように展開されていても、SQL も Python も「気にしません」。構文が正しい限り、両方の言語はそれを受け入れてくれるでしょう。
複数行のフォーマットを使用することは、コードを読む人 (たとえそれが将来のあなただけだとしても!) の利益のためではありますが、また一方で、コードをより読みやすく理解しやすいものにするのに非常に役立ちます。
同じことが SQL における演算子の大文字化についても当てはまります。 これは幅広く使用されている慣習で強く推奨されますが、実際にコードを実行するソフトウェアは大文字と小文字を区別せず、「CREATE TABLE teacher」と「create table teacher」を同じコマンドとして扱います。

このコードを実行すると、成功メッセージが表示されます。また、MySQL サーバーのコマンドラインクライアント内で、テーブルが作成されているかを確認できます:
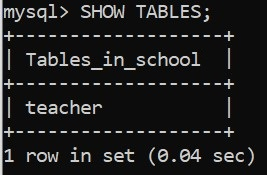
素晴らしい! では残りのテーブルを作成しましょう。
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)
これで 4 つの実体のために必要な、4 つのテーブルが作成できました。
ここで、テーブルの間の関係を定義し、さらに受講者と講座のテーブルの間の、多対多の関係を扱うために、もう 1 つテーブルを作成しなければなりません。 (詳細はこちらをご覧ください) 。
全く同じ方法でこれを行います:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)
これで、適切な制約、主キー (プライマリーキー) 、および外部キーの関係とともにテーブルが作成されました。
テーブルにデータを追加する
次のステップではテーブルにレコードを追加します。execute_query を再度使用して、用意した SQL コマンドをサーバーに与えます。では再び講師のテーブルから始めましょう。
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)
これは機能するでしょうか? MySQL コマンドラインクライアント内でもう一度確認してみましょう:
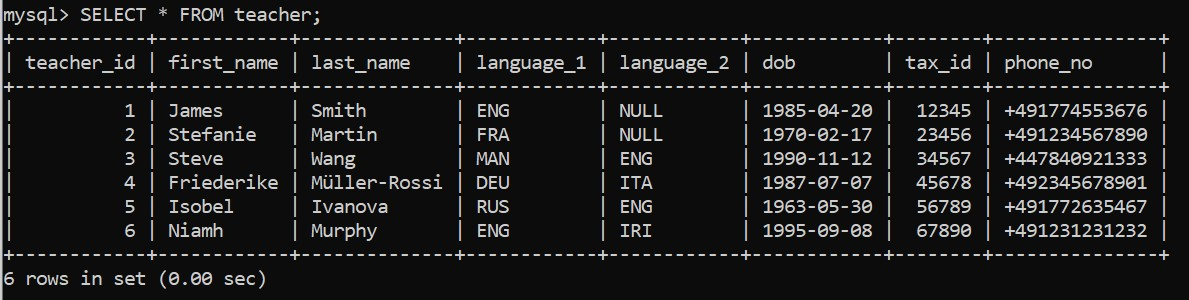
では残りのテーブルにデータを追加します。
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)
すばらしい!これで、Python のコマンドだけを使用して、MySQL の関係、制約、およびレコードを含むデータベースを、完全に作成しました。
データベースの作成について段階を追って理解しやすいように進めました。とはいえ、これまでの内容でそのすべてが 1 つの Python スクリプトだけで非常に簡単に記述でき、ターミナル内の 1 つのコマンドだけで実行できるということが確認できます。これは強力なものです。
データの読み取り
これで機能するデータベースができ、それを扱う仕事ができるようになりました。データアナリストとして、あなたは働いている組織内の既存のデータベースと関わることがあるかもしれません。 既存のデータベースの外にデータを取り出す方法を知っていると、それを Python のデータパイプラインへ与えることができるようになるので、非常に役に立ちます。それこそが次に取り組もうとしていることです。
そのためには、もうひとつ関数が必要になります。今回は cursor.commit() ではなくて cursor.fetchall() を使用します。この関数を使用して、何も変更することなくデータベースからデータを読み取ります。
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")
ここでもう一度、execute_query とよく似た方法でこれを実装します。この関数がどのように動作するのかを確認するために、シンプルなクエリを試してみましょう。
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)
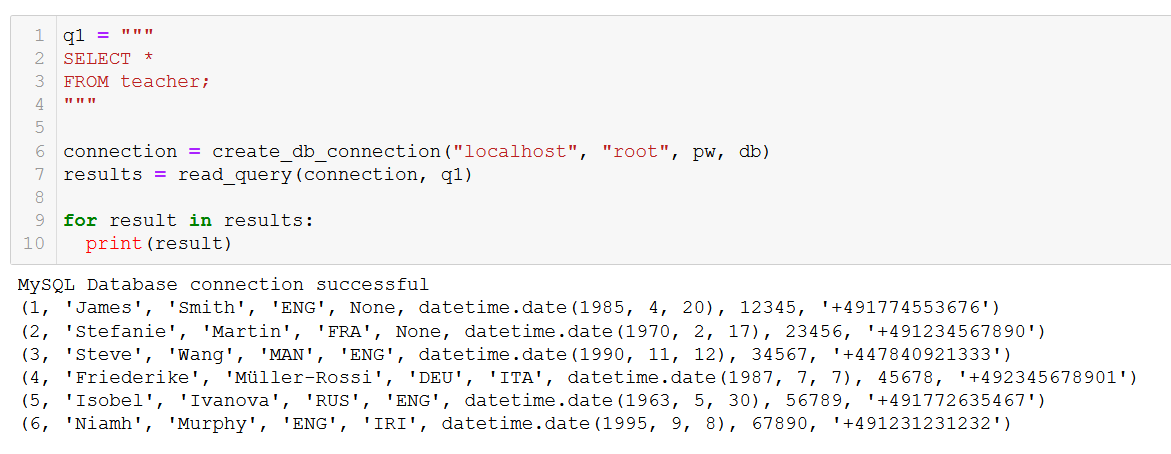
まさに期待していた結果が得られました。次のような講座と法人顧客のテーブルの結合 (JOIN) を含む、より複雑なクエリでもこの関数は機能してくれます。
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)
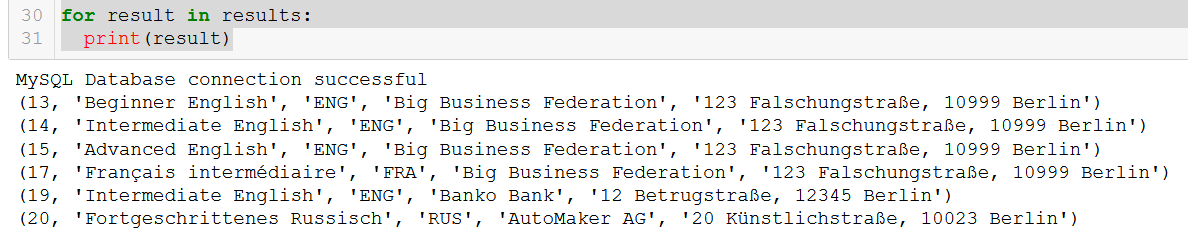
とてもいいですね。
Python におけるデータパイプラインとワークフローでは、さらに役に立つようにするため、または操作するための準備を行うために、読み取ったデータを異なる形式で取得したいと考えることがあるかもしれません。
それができるようになる方法の例をいくつか見ていくことにしましょう。
出力をリストの形式に変換する
# 空リストで初期化します
from_db = []
# results をループ処理してデータをリストの中に追加します
# タプルのリストを返します
for result in results:
result = result
from_db.append(result)

出力を 2 次元リストの形式に変換する
# 2 次元リストを返します
from_db = []
for result in results:
result = list(result)
from_db.append(result)

出力を pandas の DataFrame 形式に変換する
Python を使用するデータアナリストにとって、pandas は非のうちどころがなくて信頼できる昔からの友達です。データベースの出力をデータフレームに変換するのは非常に簡単で、さらにそこから無限の可能性が得られます!
# 2 次元リストを返し、さらにそこから pandas のデータフレームを作成します
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)
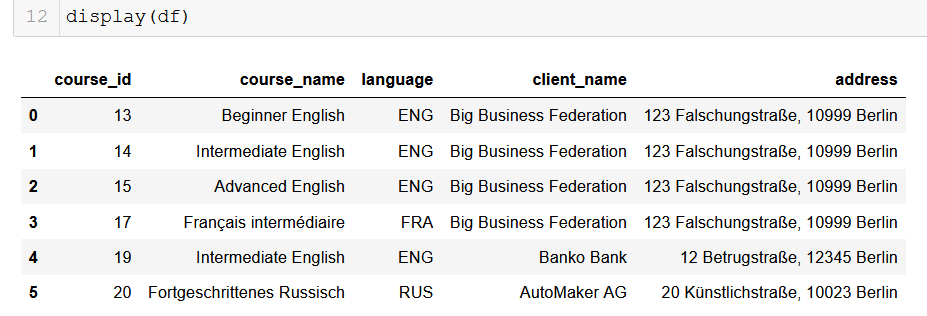
うまくいけば、ここで目の前に広がっている可能性を見ることができるでしょう。 たった数行のコードで、処理できるすべてのデータを、リレーショナルデータベースがあるところから簡単に取り出すことができ、さらにそれを最先端のデータ分析パイプラインの中に取り込むことができます。これは本当に役に立つものです。
レコードを更新する
データベースを管理している時に、既存のレコードの変更が必要な場合があります。このセクションではその方法について見ていきましょう。
例えば ILS が、既存の法人顧客のひとつである Big Business Federation から、オフィスを 23 Fingiertweg, 14534 Berlin に移転します、という通知を受けたとしましょう。この場合、データベースの管理者 (私たちのことです!) は、いくつか変更を行う必要があります。
幸い、SQL の UPDATE 文と一緒に execute_query 関数を使用することで、それができるようになります。
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)
ここでは、WHERE 句が非常に重要である点に注意してください。 WHERE 句無しでこのクエリを実行した場合、法人顧客テーブル内の全レコードのすべての住所が、23 Fingiertweg に更新されます。それは私たちが望んでいることではありません。
また、UPDATE クエリの中で 「WHERE client_id = 101」を使用していることにも注意してください。「WHERE client_name = 'Big Business Federation'」または「WHERE address = '123 Falschungstraße, 10999 Berlin'」も使用できますし、さらに「WHERE address LIKE '%Falschung%'」を使用することも可能でした。
ここで重要なことは、WHERE 句を使用すると、更新しようとしているひとつ (または複数) のレコードを一意的に特定できるということです。
レコードを削除する
DELETE 文とともに execute_query 関数を使用することでレコードを削除できます。
リレーショナルデータベースで SQL を使用する場合は、DELETE 演算子の使用には注意が必要です。Windows とは違い、「削除してもよろしいでしょうか?」という警告ポップアップはありませんし、ごみ箱もありません。一度何かを削除してしまうと、本当になくなってしまうのです。
とはいえ、本当に物事を削除する必要がある時もあります。それでは、コーステーブルからコースを 1 つ削除して、その方法を見てみましょう。
まずはじめに、どういったコースがあるのかを思い出してみましょう。
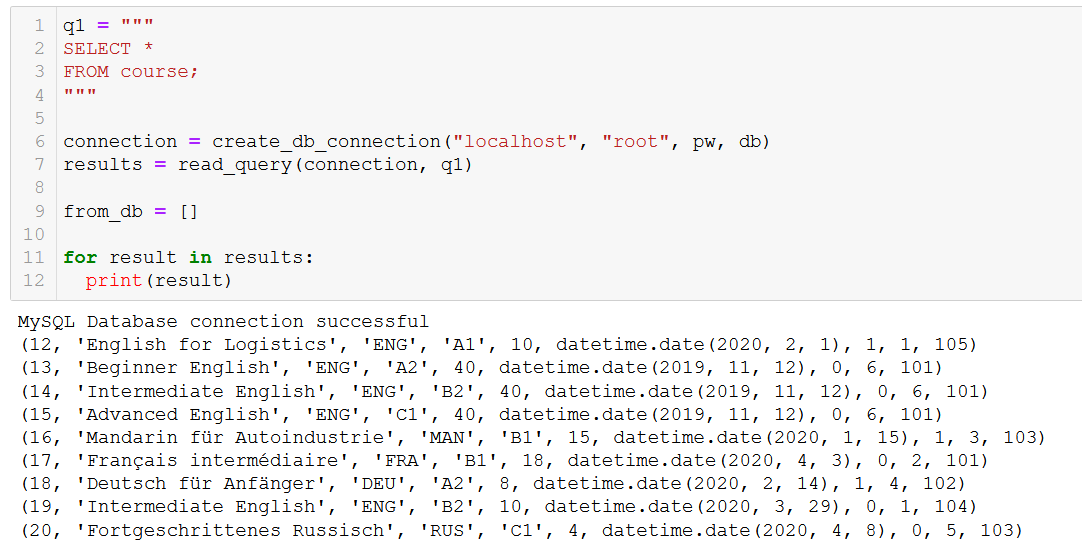
仮に、20 番のコース「Fortgeschrittenes Russisch」(これは「上級ロシア語」という意味です) がもうすぐ廃止になるので、それをデータベースから削除する必要があるとしましょう。
ここまで来れば、それを行う方法について驚かされることは全くないでしょう - SQL コマンドを文字列として保存し、それを主力の execute_query 関数に渡します。
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)
意図した結果となったか確認してみましょう:
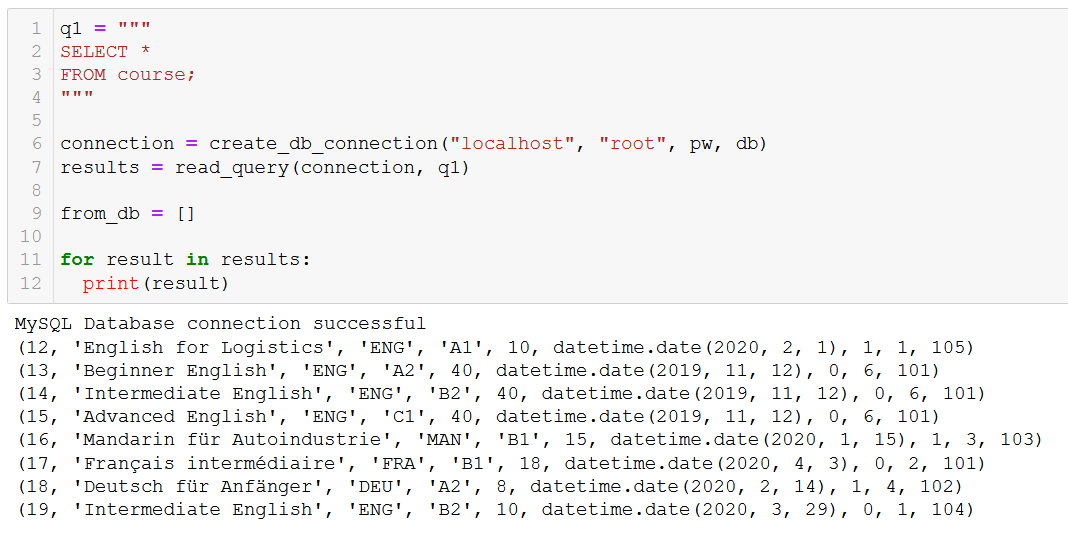
期待していた通りに、「上級ロシア語」はなくなりました。
この方法は DROP COLUMN コマンドを使用して列全体を削除したり、DROP TABLE コマンドを使用してテーブル全体を削除する場合にも機能しますが、このチュートリアル内ではそれらは扱いません。
ですが、思い切ってそれらを試してみてください - 架空の学校用のデータベースから列やテーブルを削除してもかまいません。本番環境を手掛ける前にこれらのコマンドに慣れておくことをお勧めします。
おぉ、CRUD です
この時点で、永続的なデータ記憶装置の 4 つの主な操作を完了させることができるようになりました。
学習した操作を以下に挙げます:
- 生成 (Create) - 全く新しいデータベース、テーブル、レコードを生成する
- 読み取り (Read) - データベースからデータを取り出し、複数の形式でそのデータを保存する
- 更新 (Update) - データベース内の既存のレコードに変更を加える
- 削除 (Delete) - 不要になったレコードを削除する
これらは途方もなく便利で、実行可能なものです。
ここで学習を終える前に、もう 1 つとても便利なスキルを学びます。
リストからレコードを作成する
テーブルを追加する際に、execute_query 関数内で SQL の INSERT コマンドを使用して、データベースの中にレコードを書き込めることを確認しました。
私たちが SQL データベース を操作するのに Python を使用していることを考慮すると、Python の (リストなどの) データ構造を使用して、データベースの中に直接レコードを挿入できると便利です。
これは例えば、Python で記述したソーシャルメディアアプリ上のユーザーの活動履歴を保存したい場合、または作成した Wiki の中にユーザーからの入力を保存したい場合に役に立ちます。これについては考えられる限り多くの、実行できる用途があります。
この方法は、データベース全体を破損または破壊さえする可能性のある、SQL インジェクション攻撃を防ぐのに役に立つので、データベースがいつでもユーザーに公開されている場合にはより安全です。
ではこれを行うために、これまでに使用していたより単純な execute() メソッドの代わりに、executemany() メソッドを使用する関数を記述しましょう。
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")
これで関数ができたので、SQL コマンド ('sql') と、データベースの中に入れようとしている値を含むリスト ('val') を定義する必要があります。この値は、タプルのリストとして保存されなければなりません。これは Python においてデータを保存するのに広く定着している方法です。
では次のようなコードを記述して、新しい 2 人の講師をデータベースに追加します:
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]
'sql' コードの中で、値のプレースホルダーとして '%s' を使用していることに注意してください。 Python の文字列に対する '%s' プレースホルダーとの類似はただの偶然です (そして実のところ、非常に紛らわしいです) 。Python の MySQL Connector では (文字列、整数、日付などの) すべてのデータ型に '%s' を使用します。
Python で '%d' プレースホルダーを整数に対して使用することに慣れてしまっているために、そうしようとして混乱してしまっている人からの数多くの質問を、Stackoverflow で見ることができます。'%d' は、ここでは機能しません - 値を追加しようとする列ごとに '%s' を使用する必要があります。
その後で、executemany 関数は 'val' リスト内の各タプルを取得し、プレースホルダーの代わりにその列に関連する値を挿入し、リストの中に含まれている各タプルに対して SQL コマンドを実行します。
これは適切にフォーマットしてさえいれば、複数行のデータに対して実行できます。この例では、説明のために新しい講師を 2 人だけ追加しますが、原則として、必要な数を追加できます。
では先に進んで、このクエリを実行してデータベースに講師を追加しましょう。
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)
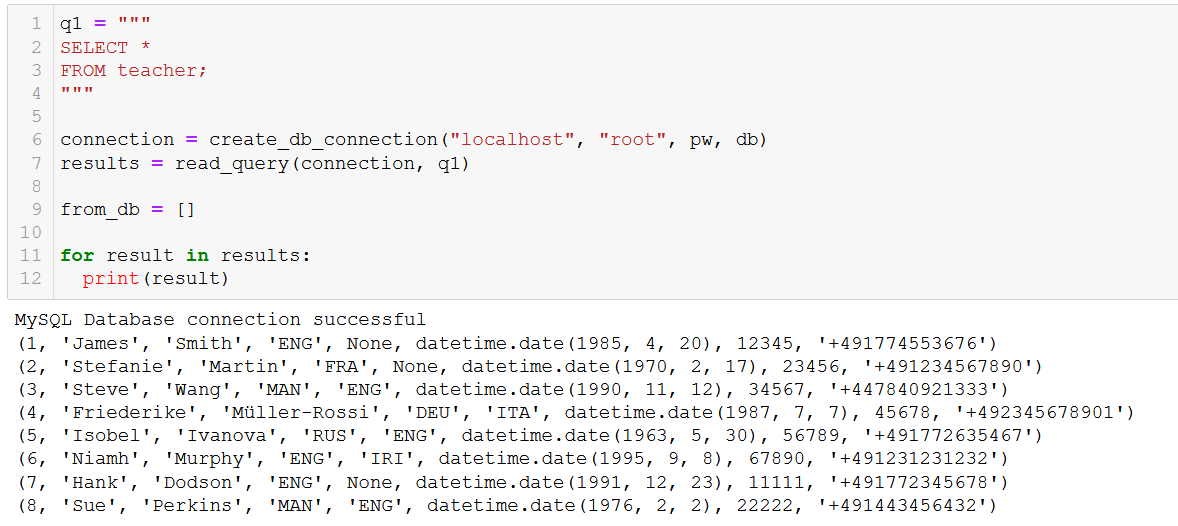
ILS へようこそ、Hank さんと Sue さん!
これはもう 1 つの非常に便利な関数で、Python スクリプトやアプリケーション内で生み出されたデータを取得して、それらをデータベースの中に直接入れることができます。
結論
このチュートリアルでは多くの話題を取り扱いました。
Python と MySQL Connector を使用して、全く新しいデータベースを MySQL サーバー内に作成し、そのデータベースの中にテーブルを作成し、それらのテーブルの間の関係を定義し、テーブルにデータを追加する方法を学びました。
データベース内のデータを生成し、読み取り、更新し、削除する方法を取り上げました。
既存のデータベースからデータを取り出し、それらを pandas の DataFrame に投入し、分析の準備を整え、PyData スタックによって提供されるすべての可能性を活用してさらに作業する方法を見てきました。
逆に、Python のスクリプトとアプリケーションによって生み出されたデータを取得し、そのデータを後の検索や操作のために安全に保存できるデータベースの中に書き込む方法についても学習しました。
Python と SQL を一緒に使用して、データをより効率的に操作できる方法を調べるために、このチュートリアルが役に立てたならば幸いです!
もし私のプロジェクトや仕事をさらに見てみたいならば、craigdoesdata.de にある私のウェブサイトを訪問してください。このチュートリアルに関するフィードバックがあれば、直接私までご連絡ください 。すべてのフィードバックを温かくお迎えいたします!