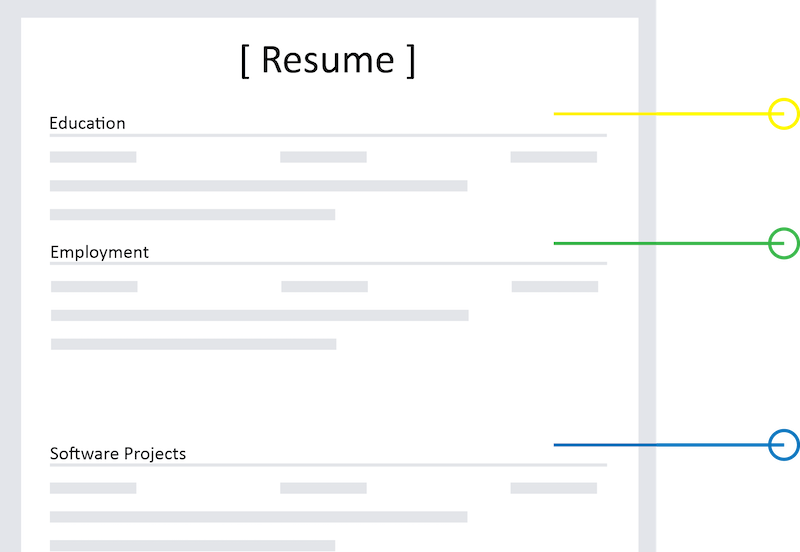
#Software Engineering How to write a Software Engineering resume (CV): the definitive guide (Updated for 2019)